


A temperatura em modelos de linguagem (LLMs) é um parâmetro de ajuste que controla a aleatoriedade na geração de texto.
Basicamente, a temperatura influencia a distribuição de probabilidade que o modelo atribui às próximas palavras ou tokens durante a geração de texto.
Configurar a temperatura corretamente pode resultar em saídas que variam de altamente criativas a mais previsíveis e seguras.
Quando a temperatura é baixa (próxima de zero), o modelo tende a ser mais conservador, escolhendo palavras de maior probabilidade.
Isso resulta em textos mais coerentes, mas pode também levar a respostas repetitivas ou clichês.
Por outro lado, uma temperatura alta aumenta a aleatoriedade, o que pode resultar em saídas criativas, porém menos coerentes.
Não sabe ao certo o que é Inteligência Artificial? Clique Aqui.
Como a Temperatura Impacta a Geração de Texto?
A temperatura tem um efeito profundo na diversidade e criatividade do texto gerado.
Em termos técnicos, ela ajusta a “suavidade” da distribuição de probabilidade para a próxima palavra que o modelo escolherá.
Vamos analisar juntos alguns aspectos importantes!
Temperatura Baixa
Com uma configuração de temperatura baixa (por exemplo, 0.5), o modelo dará maior prioridade a palavras com alta probabilidade.
O texto tende a ser mais conservador e menos propenso a erros, mas a criatividade é limitada.
Temperatura Alta
Com uma temperatura alta (por exemplo, acima de 1.0), o modelo explora mais opções de palavras, o que aumenta a criatividade.
Entretanto, isso pode levar a saídas menos coerentes e potencialmente sem sentido.
A escolha da temperatura depende do objetivo do conteúdo gerado.
Para textos técnicos, jurídicos ou informativos, uma temperatura mais baixa é geralmente preferível.
Para conteúdos criativos ou literários, uma temperatura mais alta pode ser vantajosa.
Ajustando a Temperatura: Estratégias e Exemplos Práticos
Ajustar a temperatura requer uma compreensão sólida do equilíbrio necessário para o tipo específico de saída desejada.
Vamos discutir algumas estratégias e exemplos práticos para otimizar este parâmetro.
Experimentação Passo a Passo
Testar, por meio um prompt padrão, diferentes valores de temperatura em pequenos incrementos (por exemplo, 0.4, 0.6, 0.8) para observar como cada ajuste influencia a saída.
Esta abordagem empírica ajuda a entender qual configuração produz os melhores resultados para o caso de uso específico.
Análise do Contexto
Adaptar a temperatura de acordo com o contexto do texto gerado.
Por exemplo, em um chat de atendimento ao cliente, uma temperatura neutra seria a ideal para respostas precisas e consistentes.
Já em um gerador de histórias, aumentar a temperatura pode proporcionar narrativas mais interessantes e cativantes.
Esta temperatura vai depender igualmente dos aspectos de treinamento e de configuração do modelo, logo, fique atento(a).
Feedback Iterativo
Incorporar feedback humano (RLHF) para ajustar a temperatura pode ser uma escolha prudente.
Isto envolve a análise crítica de saídas geradas por diferentes temperaturas e ajustando com base em preferências ou requisitos específicos.
Exemplos práticos
Pergunta: “O que é um buraco negro?”
Temperatura 𝑡 = 0.7: “Um buraco negro é uma região do espaço onde a gravidade é tão forte que nada, nem mesmo a luz, pode escapar.”
Temperatura 𝑡 = 1.5: “Um buraco negro é uma região do espaço conhecida por sua intensa gravidade, capaz de atrair tudo ao seu redor, incluindo luz, matéria e energia, criando um vórtice misterioso e fascinante.”
Limitações e Desafios na Regulação da Temperatura
Apesar de suas vantagens, a regulação da temperatura possui algumas limitações e desafios.
Um dos principais é o risco de overfitting, onde um ajuste muito fino da temperatura pode fazer o modelo se adaptar excessivamente aos dados de treinamento, resultando em saídas menos generalizáveis.
Outro desafio é a falta de uma “fórmula mágica” ou “bala de prata” para todas as situações.
O ajuste da temperatura é altamente dependente do contexto e do objetivo do usuário, tornando-o um processo que muitas vezes requer tempo e experimentação.
Modelos de linguagem tendem a ser sensíveis a mudanças na temperatura, o que pode resultar em comportamentos imprevisíveis.
Portanto, é crucial realizar testes rigorosos e monitorar as saídas para garantir a qualidade e a coerência desejadas.
Em alguns LLMs, especialmente aqueles que permitem interação do usuário somente por meio de um chat (para o público amplo, para quem não é especialista), a configuração de temperatura pode não estar disponível diretamente para o ajuste.
Nesses casos, o sistema usa um valor padrão de temperatura, geralmente configurado em 1, que é um equilíbrio entre previsibilidade e criatividade.
A Equação Matemática da Temperatura
Nos LLMs (assim como ChatGPT, Gemini, Claude ou outros), a escolha dos tokens de resposta é feita através de uma distribuição de probabilidade gerada pela função softmax.
Esta função transforma as pontuações (logits) atribuídas a cada token em probabilidades.
Um parâmetro fundamental nesta transformação é a temperatura, representada por “𝑡”.
A equação da função softmax com ajuste de temperatura é:

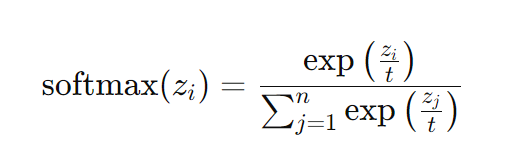
Nos modelos de linguagem, 𝑧𝑖 representa a pontuação ou logit atribuída a cada token potencial de saída.
Desta forma, o parâmetro 𝑡 (temperatura) controla a suavidade da distribuição de probabilidade dos tokens.
Impacto nos Tokens de Resposta
Quando 𝑡 é pequeno, a função exponencial acentua as diferenças entre os logits 𝑧𝑖, fazendo com que o modelo tenha maior probabilidade de escolher o token com a maior pontuação.
Quando 𝑡 é grande, as diferenças entre os logits 𝑧𝑖 são menos acentuadas, permitindo uma maior probabilidade de selecionar tokens com pontuações mais baixas.
Resumindo, ao ajustar a temperatura (𝑡), modificamos a “distribuição de suavização” das probabilidades das próximas palavras, influenciando diretamente na criatividade e coerência do texto gerado.
Conclusões
Compreender e ajustar a temperatura em Modelos de Linguagem de Grande Escala é fundamental para alcançar os resultados desejados na geração de texto.
Seja visando coerência em textos técnicos ou criatividade em narrativas literárias, a escolha correta da temperatura pode ser a diferença entre uma saída excelente e outra mediana.
A experimentação cuidadosa, análise do contexto e feedback constante são essenciais para otimizar este parâmetro.
A regulação eficaz da temperatura ajuda a equilibrar entre a precisão e a criatividade, permitindo que modelos de linguagem gerem textos que atendam às necessidades específicas dos usuários.
Inscreva-se para receber mais informações e atualizações sobre as melhores práticas em inteligência artificial, diretamente em seu e-mail.