

Conteúdo Atualizado em 27 de abril de 2025 por felipecferreira, enjoy!
A combinação de múltiplos Modelos de Linguagem de Grande Porte (LLMs) em uma única abordagem, conhecida como Mixture-of-Agents (MoA), tem sido uma estratégia amplamente adotada para buscar melhorar a geração de respostas obtidas por inteligência artificial..
No entanto, um estudo recente questiona essa prática, sugerindo que misturar diferentes modelos nem sempre é um “bom negócio”..
Seja muitíssimo bem vindo(a) a uma nova revisão de um importante paper publicado agora em fevereiro de 2025..
Título original: Rethinking Mixture-of-Agents: Is Mixing Different Large Language Models Beneficial?
Nossa tradução (didática): Repensando mix-de-agentes: misturar diferentes Large Language Models é realmente benéfico?
A pesquisa desenvolvida por Wenzhe Li et al (2025), introduz uma nova abordagem chamada Self-MoA, que propõe que utilizar múltiplas amostras de um único modelo de alto desempenho pode ser mais eficaz do que combinar modelos distintos.
Você pode acessar o paper em inglês e na íntegra, clicando aqui.
O Mito da Diversidade de Modelos (Mixed-MoA)?!
A abordagem tradicional, conhecida como Mixture-of-Agents (MoA), busca combinar as forças de diferentes LLMs para resolver tarefas complexas.
A ideia é que, ao reunir uma variedade de “especialistas” (modelos como GPT-4o, Gemini 2.0, Claude Sonnet, DeepSeek V3, etc.), podemos obter um resultado final superior, compilando as diferentes respostas para uma única solução.
Imagine um comitê de especialistas em diversas áreas, cada um contribuindo com sua expertise para solucionar um problema.
Essa é a essência do Mixed-MoA.
No entanto, o estudo da Universidade de Princeton revela que essa busca pela diversidade pode ter um lado negativo:
Qualidade comprometida: Ao incluir modelos de baixa qualidade na “mistura de inputs, para a versão final”, o desempenho geral pode ser prejudicado, pois esta resposta será agregada as demais e pode comprometer a consistência ou razoabilidade das informações.
Trade-off inevitável: Existe um equilíbrio delicado entre diversidade e qualidade. A busca por uma variedade maior de modelos pode inadvertidamente levar à inclusão de opções menos competentes (considerando variáveis como o tamanho do modelo – parâmetros; fine-tuning; penalizações e outros setups que podem estar fora do alcance de ajuste pelo usuário, etc.).
Compreendendo as Diferenças Práticas entre o MoA, Self-MoA e Self-MoA-Seq
Vamos a uma imagem direta do artigo:
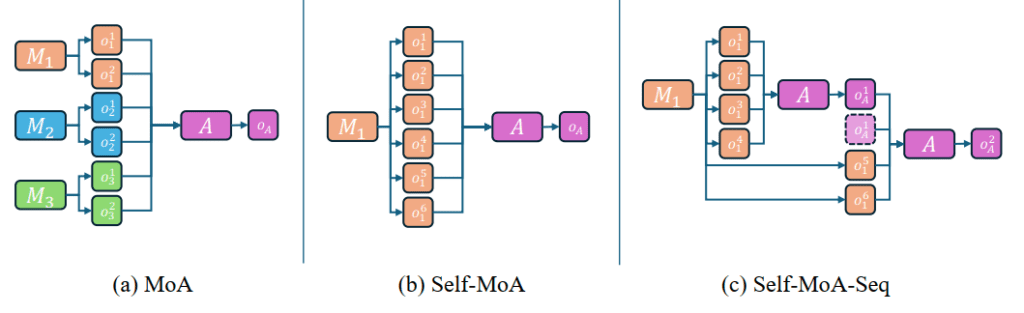
A imagem acima apresenta uma comparação entre três métodos para agregar respostas de Modelos de Linguagem de Grande Porte (LLMs):
(a) MoA (Mixture-of-Agents)
Consulta múltiplos modelos para gerar respostas, isto é, você quer escrever um post para Blog sobre Jejum Intermitente.
Logo, você elabora um prompt explicando como quer a produção de conteúdo, fornece fontes (pdfs, sites, etc.) e usa o exato prompt para diferentes modelos (GPT, Mistral, Qwen, etc.).
Depois de ter todos os potenciais artigos em mãos, você utiliza um modelo agregador seleciona e sintetiza a melhor resposta final.
Essa abordagem busca diversidade, mas pode comprometer a qualidade ao misturar modelos inferiores (ou consideravelmente díspares).
(b) Self-MoA
Em vez de misturar modelos diferentes, ele amostra múltiplas respostas do mesmo modelo de alto desempenho.
Isso reduz a variação de qualidade e melhora a consistência das respostas.
No benchmark AlpacaEval 2.0 (avalia a qualidade das respostas de modelos de linguagem de forma comparativa), Self-MoA demonstrou 6,6% de melhora em relação ao MoA tradicional.
Nos conjuntos de dados MMLU (Massive Multitask Language Understanding – avalia o conhecimento geral e a capacidade de raciocínio dos modelos, CRUX (avalia a capacidade dos modelos de justificar suas respostas) e MATH (conjunto de testes focado exclusivamente em problemas matemáticos complexos, abrangendo álgebra, cálculo, probabilidade e geometria), a abordagem garantiu um ganho médio de 3,8% na precisão das respostas
(c) Self-MoA-Seq
Uma versão escalável do Self-MoA, onde as amostras são agregadas passo a passo.
Resolve limitações de comprimento de contexto (context window) dos modelos, permitindo uma síntese mais eficiente de múltiplas respostas.
Essa comparação ilustra que priorizar qualidade em vez de diversidade pode gerar respostas mais precisas e úteis, desafiando a ideia de que misturar modelos sempre traz benefícios.
Aplicações Práticas e Implicações para o Mercado
Recapitulando..
Felipe, como seria isso na prática?!
Você pode solicitar ao seu modelo de preferência, como o GPT-4o gerar um “mesmo artigo” 5 vezes, sem mudar o prompt (important!).
Cada versão de saída será (sutilmente) diferente, pois os modelos de IA sempre introduzem variações naturais na geração de texto.
Nota: Essa variação funciona porque os LLMs são probabilísticos, ou seja, mesmo com o mesmo prompt e o mesmo modelo, a resposta pode variar a cada geração, especialmente se usarmos temperaturas mais altas ou técnicas como sampling (o processo em que o modelo de IA escolhe palavras de forma probabilística ao gerar uma resposta).
No final, você pode comparar e combinar as melhores partes das 5 versões, sintetizando o artigo final manualmente..
Ou pegar o mesmo modelo e solicitar para que ele reajuste uma versão final com as melhores partes (aí vai do seu prompt e da sua intimidade em trabalhar com LLMs).
Na Prática, eu também testaria, por exemplo, solicitar a um modelo superior para fazer essa “versão final”, como o o1 ou o3-mini (mantendo o exemplo com a “família” OpenAI).
E o que mais tudo isso significa para o mundo da inteligência artificial e suas aplicações práticas?
Otimização de recursos: Em vez de investir em uma variedade de modelos, as empresas podem concentrar seus esforços em aprimorar um único LLM de alta qualidade.
Isso pode gerar economias significativas e simplificar o processo de desenvolvimento, obviamente, desde que o modelo selecionado comporte todas as funcionalidade de atendimento – multimodal).
Aplicações em áreas específicas: O Self-MoA se mostra particularmente eficaz em tarefas que exigem alta precisão e consistência, como:
[1] Análise de dados: Extrair informações valiosas de grandes conjuntos de dados.
[2] Geração de código: Desenvolver trechos de códigos, funções, testar e retirar bugs, etc.
[3] Resolução de problemas matemáticos: Encontrar soluções para desafios complexos.
[4] Produção de conteúdo: desenvolvimento de roteiros de vídeo, copys para publicidade geral, scripts de vendas, etc.
Considerações Finais da Revisão do Self-MoA
Achei muito interessante esse paper com os achados práticos da pesquisa..
Eu mesmo nunca pensei antes em aplicar esta estratégia para a execução de prompts, apesar de sempre triangular respostas, mais no intuito de validar a minha ideia e a consistência da informação nos múltiplos modelos que acesso todos os dias..
Principalmente quando o assunto é matemática e busca por informações na internet..
O que eu costumo falar é que, ter contato todos os dias com tecnologia, ler um pouco sobre os avanços e desenvolvimentos do mercado, abre a nossa mente e o cinto de utilidades para o trabalho real no dia-a-dia com inteligência artificial..
E eventualmente, ganhamos mais e/ou trabalhamos melhor.
Gostou deste conteúdo?
Quer se aprofundar ainda mais no universo da Inteligência Artificial e suas aplicações no marketing e aquisição de clientes?
É só clicar em algum lugar aqui da tela, tem um botão do WhatsApp e eu falo com você.
Referência
LI, Wenzhe et al. Rethinking Mixture-of-Agents: Is Mixing Different Large Language Models Beneficial?arXiv:2502.00674v1 [cs.CL] 2 Feb 2025