

Conteúdo Atualizado em 24 de março de 2025 por felipecferreira, enjoy!
Arquiteturas, Modelos e Aplicações
A Multimodalidade na Inteligência Artificial, ou IAs Multimodais, permitem a interpretação e o cruzamento de diferentes tipos de dados (como texto, imagem, áudio e vídeo) em uma única arquitetura coesa.
Historicamente, os sistemas de IA eram desenhados para trabalhar com um único tipo de entrada.
Um modelo de linguagem processava apenas texto; uma rede convolucional operava somente sobre imagens.
Esse paradigma unimodal impunha limites significativos em termos de contexto, robustez e adaptabilidade.
Já a IA Multimodal busca espelhar a cognição humana, que naturalmente integra múltimos sentidos para formar compreensão e tomar decisões.
Vamos compreender melhor as diferenças e alguns aspectos técnicos relevantes!
1. IA Unimodal vs. IA Multimodal
A distinção entre IA Unimodal e Multimodal está no tipo e na diversidade dos dados que cada abordagem é capaz de processar.
1.1 IA Unimodal: Foco em uma única modalidade
Sistemas unimodais são projetados para interpretar apenas uma forma de dado por vez.
Modelos como redes convolucionais (CNNs) aplicadas à visão computacional ou transformadores treinados exclusivamente para linguagem natural (como o BERT) são exemplos clássicos dessa arquitetura.
Neles, tanto o input quanto o output permanecem dentro da mesma modalidade (por exemplo, texto-para-texto ou imagem-para-imagem).
Embora altamente eficazes dentro de seus domínios específicos, os modelos unimodais possuem limitações estruturais:
Reduzida compreensão de contexto quando o conteúdo depende de múltiplos sinais (ex: tom de voz + palavras).
Fragilidade diante de ruídos ou dados ausentes, já que dependem de uma única fonte de informação.
Incapacidade de executar tarefas que exigem raciocínio entre modalidades (como pedir a análise de imagens, áudios e texto para a resolução ou diagnósticos de um determinado problema).
1.2 IA Multimodal: Integração sensorial e raciocínio cruzado
A IA Multimodal, por outro lado, é desenhada para fazer inferências a partir da combinação de múltiplos dados heterogêneos.
Isso pode incluir, por exemplo, a análise simultânea de uma imagem, uma legenda textual e um áudio descritivo.
Tecnicamente, isso exige: Múltiplos encoders especializados, um para cada tipo de entrada (texto, imagem, áudio, etc.).
Mecanismos de alinhamento e fusão, como atenção cruzada (cross-attention), para integrar e relacionar os embeddings multimodais.
Uma arquitetura robusta, frequentemente baseada em Transformers generalistas (como o GPT-4o e o Gemini), capazes de gerar saídas em uma ou mais modalidades.
As vantagens da abordagem multimodal incluem:
Maior robustez a falhas ou ausência de informações em um dos canais.
Capacidade de generalização em tarefas complexas que exigem cruzamento semântico de contextos distintos.
2. Arquitetura dos Sistemas Multimodais
A arquitetura dos sistemas multimodais é composta por diferentes módulos especializados que colaboram para processar, integrar e gerar informações oriundas de múltiplas fontes de dados heterogêneos.
O desafio central está em construir estruturas capazes de manter a coerência semântica entre modalidades distintas (como imagem, texto, áudio e vídeo), respeitando suas representações próprias e extratores de características.
A imagem abaixo ilustra o processamento de entradas multimodais e pipeline de fusão tardia (Late Fusion – detalharemos na sequência), no setor da medicina.
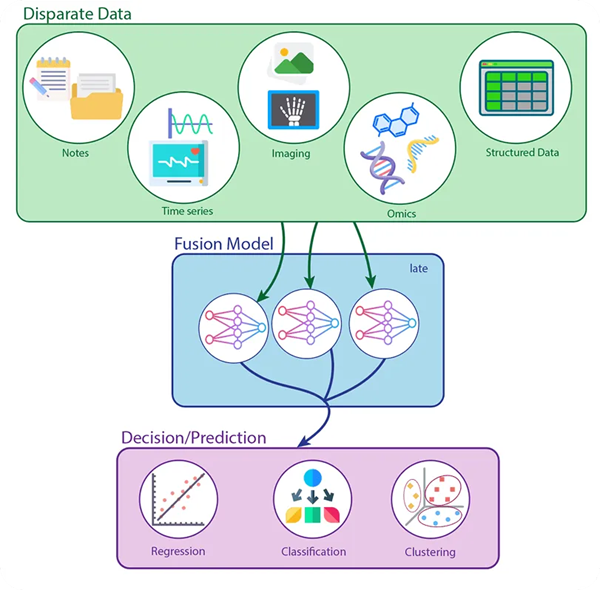
Na parte superior, vemos a origem dos dados, que podem incluir anotações textuais (notes), séries temporais (como sinais vitais), imagens médicas, dados genéticos (ômicos) e dados estruturados (como tabelas).
Cada tipo de dado é processado de forma independente por modelos especializados, representados por redes neurais distintas no bloco azul.
Isso permite que cada rede aprenda representações profundas e específicas antes de combiná-las em um módulo comum de decisão.
Por fim, as representações são consolidadas em uma etapa final que gera uma predição unificada, que pode assumir a forma de uma regressão, classificação ou agrupamento (clustering), dependendo do objetivo do sistema (suporte, diagnóstico).
Essa estratégia é especialmente útil quando as modalidades são heterogêneas demais para serem fundidas diretamente desde o início, um cenário comum em ambientes biomédicos ou industriais.
Tendo feito esta introdução ilustrativa, vamos analisar um pouco mais afundo os principais módulos..
2.1 Módulos Principais
2.1.1 Módulo de entrada
Cada tipo de dado exige um processador especializado, geralmente, uma rede neural adaptada para extrair embeddings de alto nível.
Exemplos:
Texto: Modelos baseados em Transformers, como BERT ou T5.
Imagem: Redes convolucionais (CNNs) ou vision transformers (ViT).
Áudio: Redes recorrentes, CNNs temporais ou encoders como Whisper.
O papel deste módulo é transformar a entrada bruta em representações vetoriais latentes específicas de cada domínio, mantendo a riqueza semântica e estrutural da informação.
2.1.2 Módulo de interação cruzada (cross-modal interaction)
Este módulo é responsável por mapear e alinhar semanticamente as diferentes representações.
É aqui que ocorre o cruzamento entre modalidades, por meio de mecanismos como:
Cross-attention: permite que embeddings de uma modalidade (por exemplo, imagem) prestem atenção em outra (como texto).
Gate mechanisms: filtram ou priorizam informações de cada modalidade com base no contexto.
Co-attention: atenção bidirecional entre dois domínios, ajustando pesos de relevância em ambos os sentidos.
Esse alinhamento é crítico para tarefas como Visual Question Answering, onde a compreensão correta depende da interação entre imagem e linguagem natural.
2.1.3 Módulo de fusão
Após o alinhamento, as representações devem ser fundidas em uma única estrutura semântica que alimente o modelo de decisão.
Existem três abordagens principais:
Early Fusion: combinação das entradas ainda em seus formatos brutos ou em estágios iniciais de codificação. Exige modelos com alta capacidade para lidar com dados heterogêneos desde o início.
Intermediate Fusion: as modalidades são codificadas separadamente, e os embeddings intermediários são integrados em camadas ocultas. É o método mais comum em arquiteturas transformer.
Late Fusion: as saídas finais de cada modalidade são combinadas apenas no final do pipeline, geralmente em tarefas de decisão. É útil em contextos onde cada modalidade opera de forma independente.
Vamos entender melhor estas abordagens, observe a imagem abaixo:
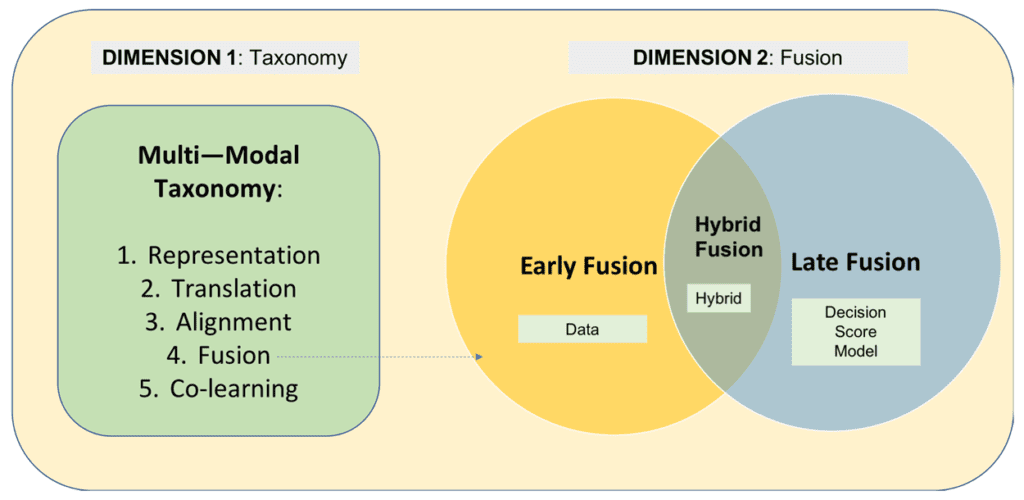
Na Dimensão 1: Taxonomia, temos um pipeline conceitual que representa as etapas do processamento multimodal, do mais básico ao mais integrado:
Representation – Cada modalidade (imagem, texto, áudio, etc.) é representada em um espaço vetorial próprio. Sem essa etapa, não é possível iniciar qualquer forma de integração.
Translation – Aqui, as representações começam a ser convertidas ou mapeadas para domínios compatíveis. É o ponto onde se testa a capacidade de uma modalidade em simular semanticamente outra.
Alignment – Uma vez traduzidas ou codificadas, as diferentes modalidades precisam ser alinhadas no espaço semântico.
Técnicas como contrastive learning ou cross-attention são usadas para garantir que vetores de texto e imagem, por exemplo, ocupem posições semelhantes quando representarem o mesmo conceito.
Fusion – Após o alinhamento, ocorre a fusão real das informações, que pode seguir abordagens como early, late ou hybrid fusion (mostradas na Dimensão 2). Essa etapa determina como os dados interagem entre si e influenciam o raciocínio da IA.
Co-learning – Na fase mais avançada, o modelo aprende de forma conjunta entre as modalidades. Ou seja, não apenas integra informações, mas aprende a aprender com elas simultaneamente, o que é comum em modelos fundacionais multimodais.
A ordem apresentada na taxonomia representa uma hierarquia funcional: cada etapa é pré-requisito conceitual e técnico para a próxima.
É um reflexo do nível de integração e complexidade que o sistema alcança na manipulação de dados heterogêneos.
Essa Dimensão 1 se conecta diretamente com a Dimensão 2-Fusion, onde as técnicas de fusão são aplicadas.
Dependendo do nível de representação, alinhamento e coaprendizado que o modelo atinge, diferentes estratégias de fusão se tornam mais apropriadas.
2.1.4 Módulo de saída
A saída pode ser unimodal (por exemplo, geração de texto a partir de imagem + áudio) ou multimodal (como texto + imagem).
A escolha depende da tarefa e da arquitetura geral (além da requisição do usuário).
O modelo pode produzir respostas, classificações, legendas, comandos, traduções ou até mesmo ações em tempo real.
2.2 Padrões de Arquitetura
2.2.1 Encoder-Decoder Multimodal
Nesta estrutura, diferentes encoders são aplicados a cada modalidade, e suas representações são fundidas antes de serem processadas por um único decoder.
O decoder pode ser especializado (por exemplo, para geração de linguagem) ou multimodal.
Essa abordagem é comum em tarefas como geração de legenda para imagens (image captioning) ou tradução de vídeos com linguagem de sinais.
2.2.2 Transformers Multimodais
Transformers adaptados para entradas multimodais são a espinha dorsal de modelos como Flamingo, GPT-4o, Gemini e Kosmos.
Eles utilizam embeddings posicionais e tokenização unificada para integrar modalidades distintas.
Muitos adotam modality-specific embeddings para diferenciar os tipos de input.
A fusão geralmente ocorre nas camadas internas, com mecanismos de atenção que correlacionam semanticamente os tokens de diferentes fontes (como explicado anteriormente).
2.2.3 Mecanismos de Atenção Cruzada (Cross-Attention)
O cross-attention é um dos pilares da arquitetura multimodal moderna.
Ele permite que o modelo aprenda a relacionar conteúdo de diferentes fontes, atribuindo pesos de relevância entre tokens de modalidades distintas.
Por exemplo, ao descrever uma imagem, o texto gerado pode focar nas áreas visuais mais informativas identificadas por meio de atenção cruzada entre regiões da imagem (bounding boxes ou patches) e palavras-chave.
Este tipo de mecanismo é amplamente utilizado em arquiteturas como ViLBERT, VisualBERT, BLIP-2 e LLaVA, permitindo raciocínios mais profundos e respostas multimodais contextualizadas.
3. Modelos Multimodais de Referência
A evolução dos modelos multimodais tem sido impulsionada por avanços em arquiteturas de transformer, treinamento em larga escala e técnicas de alinhamento semântico entre modalidades.
Abaixo, destacamos os principais modelos de referência que exemplificam os diferentes caminhos adotados por líderes da indústria para construir sistemas verdadeiramente multimodais.
>>> O GPT-4o, onde “o” representa omni, é o modelo mais recente da OpenAI com capacidade nativa de entrada e saída multimodal. Ao contrário do GPT-4 anterior, que utilizava um sistema externo (como o modelo Vision do ChatGPT) para lidar com imagens, o GPT-4o é um modelo unificado treinado de forma conjunta em texto, imagem, áudio e vídeo.
>>> O Gemini, da Google DeepMind, representa a segunda geração da linha multimodal da empresa e integra avanços notáveis em escalabilidade e persistência de contexto.
Assim como o GPT-4o, foi projetado para entrada e saída multimodal, mas se destaca por sua janela de contexto (context window) estendida, com suporte de cerca de 1 milhão de tokens.
>>> O QwQ (família de modelos Alibaba) aceita entradas híbridas como uma foto acompanhada de um áudio e/ou um vídeo com legendas.
Seu pipeline de pré-processamento normaliza e alinha os dados em um espaço latente comum , facilitando a inferência cruzada . Na geração, o modelo produz saídas em múltiplos formatos (áudio, texto e vídeo).
Se você ainda não testou (QwQ), vale muito a pena, é um modelo avançado e de acesso gratuito.
Conclusões
Ao longo deste conteúdo, exploramos não apenas os fundamentos conceituais da IA multimodal, mas também suas arquiteturas, modelos de referência, técnicas de fusão e aplicações práticas.
Essa abordagem permite à IA alcançar níveis mais elevados de compreensão contextual, raciocínio semântico e tomada de decisão, tornando-se mais próxima da cognição humana.
Nota Técnica sobre Modelos Unimodais
Embora os modelos multimodais estejam no centro da inovação em inteligência artificial, os modelos unimodais continuam sendo extremamente importantes e permanecerão relevantes por muito tempo.
Eles são especializados, mais leves computacionalmente e altamente eficientes quando aplicados a tarefas específicas..
Além disso, por exigirem menos dados e infraestrutura para treinamento e inferência, modelos unimodais são ideais para aplicações embarcadas e soluções comerciais com escopo bem definido.
Por isso, mesmo com o avanço dos modelos generalistas multimodais, os unimodais continuarão sendo uma base sólida para construções modulares, treinamento especializado e uso estratégico em pipelines híbridos de IA.
😀
Gostou deste conteúdo?
Quer se aprofundar ainda mais no universo da Inteligência Artificial e suas aplicações no marketing e aquisição de clientes?
É só clicar em algum lugar aqui da tela, tem um botão do WhatsApp e eu falo com você.