

Conteúdo Atualizado em 20 de julho de 2025 por felipecferreira, enjoy!
Das Origens ao Rascunho da URL
O termo Uniform Resource Locator (URL) nasceu para resolver um problema prático: como apontar, por meio de uma cadeia de texto única, qualquer recurso disponível na recém‑criada World Wide Web (www // a internet).
A ideia aproveitou duas peças já existentes :
(i) o Domain Name System (DNS) de 1985;
(ii) e a sintaxe de caminhos de ficheiros com barras (“/”)
E começou a ser usada nos protótipos de Hypertext Transfer Protocol (HTTP) que Tim Berners‑Lee rodava no CERN a partir de 1990.
CERN é uma sigla para Conseil Européen pour la Recherche Nucléaire (Conselho Europeu para a Pesquisa Nuclear).

Berners-Lee não apenas desenvolveu (obviamente em conjunto com colaboradores) a URL, mas também foi o cérebro por trás de outras duas tecnologias essenciais que formam a base da web como a conhecemos:
(1) o Protocolo de Transferência de Hipertexto (HTTP), que permite a comunicação entre servidores e clientes (navegadores);
(2) a Linguagem de Marcação de Hipertexto (HTML), usada para criar as páginas da web.
Vamos seguir..
O progresso da URL em 1992
O primeiro debate público: Com o rápido crescimento da Web, Berners‑Lee levou a proposta para uma sessão birds‑of‑a‑feather na The Internet Engineering Task Force (IETF – fundada em 1986), chamada “Living Documents”.
Ali surgiram as primeiras minutas do padrão, ainda usando o acrónimo UDI (Universal Document Identifier), logo substituído por URL.
O progresso da URL em 1994
Neste ponto ocorreu a Formalização da RFC 1738.
RFC é uma sigla para Request for Comments (em português, “Pedido de Comentários”).
As RFCs são uma série de publicações e documentos técnicos que descrevem padrões, protocolos e informações relacionadas à internet.
Gerenciadas pela Internet Engineering Task Force (IETF, já mencionada acima), elas são a forma como a comunidade técnica da internet propõe, debate e define as regras de funcionamento da rede.
Embora o nome sugira um pedido de comentários, muitas RFCs são, na prática, os padrões estabelecidos e seguidos globalmente.
Com estas devidas explicações, vamos seguir..
Então, em Dezembro de 1994, a IETF publicou o RFC 1738, redigido por Berners‑Lee, Larry Masinter e Mark McCahill, estabelecendo oficialmente a sintaxe e os esquemas de acesso mais comuns (http, ftp, mailto, etc.).
É aqui que o termo “Uniform” ficou definitivo, deixando “Universal” para trás.
Desenvolvimentos da URL entre 1998–2005
De URL a URI: À medida que outros tipos de identificadores como o Uniform Resource Name (URN) ganhavam força, o RFC 2396 (1998) fundiu tudo sob o guarda‑chuva de Uniform Resource Identifier (URI), tratando URL como um subtipo.
Essa consolidação foi refinada no RFC 3986 (Janeiro 2005), que continua a orientar a sintaxe genérica usada hoje (escrevo este conteúdo em julho de 2025).
De 2014 até a Atualidade
A partir de 2014, os principais fabricantes de navegadores passaram a manter a especificação de URLs como um documento vivo, isto é, o Living Standard, no Web Hypertext Application Technology Working Group (WHATWG).
O objetivo foi alinhar o código real dos browsers com uma norma única, já que vários detalhes práticos (como espaços ou barras invertidas em endereços) divergiam do texto fixo dos RFC 3986/3987.
Metas declaradas
O próprio standard descreve quatro grandes pilares:
- Harmonizar o comportamento implementado com os antigos RFCs;
- Unificar a terminologia em torno de URL, aposentando “URI/IRI”;
- Fornecer um algoritmo determinístico de parsing / serialização totalmente testável;
- Disponibilizar uma API consistente (
URL,URLSearchParams) em todo o ecossistema JavaScript.
Quais foram os Impactos práticos?
- Algoritmo único de parsing, cobrindo percent‑encoding em quatro conjuntos, tratamento de Unicode/IDNA e garantia de idempotência.
- API oficial nos navegadores e no servidor: desde o Node 10, a API WHATWG‑compliant substituiu a antiga
url.parse(), hoje classificada como “Legacy”. - Snapshots anuais (“Review Drafts”) congelam o estado da norma uma vez por ano, facilitando a adopção por outras linguagens e specs.
O “Living Standard”segue sendo atualizado, com o last update em maio deste ano (2025).
Para concluir, vamos agora analisar na prática as componentes de uma URL.
As Componentes de uma URL
Vamos agora explicar passo a passo as principais componentes de uma URL.
Observe a imagem abaixo e na sequência, escrevi um detalhamento para que você compreenda cada parte e sua respectiva função.
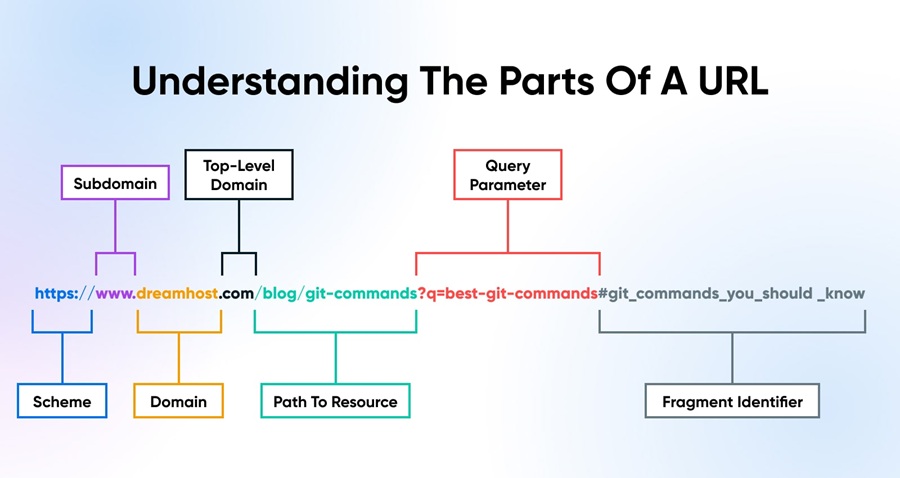
Vamos agora compreender cada bloco e claro, em Português.
- Esquema (protocolo)
É a “porta de entrada” para o recurso. Indica ao navegador (ou a outra aplicação) como estabelecer a ligação. Exemplos:http://troca dados em texto simples;https://faz o mesmo, mas encapsulado em TLS/SSL, garantindo confidencialidade e integridade;- outros esquemas comuns incluem
ftp://,mailto:efile://.
- Subdomínio
Surge antes do domínio principal, separado por ponto. Geralmente aponta para uma secção lógica do site (www.,blog.,api.). Ele permite isolar infra‑estruturas distintas (conteúdo estático, microsserviços, apps móveis) ou segmentar idiomas/regiões (en.,br.). - Domínio
O nome registrado no DNS que representa a marca ou entidade (ex.:dreamhost). Funciona como atalho memorável para endereços IP. Pode estar associado a um ou mais servidores (balanceamento, redundância). - TLD (Top‑Level Domain)
Sufixo final —.com,.org,.edu,.gov,.br, etc.- gTLDs (genéricos) não vinculam localização.
- ccTLDs (códigos de país) podem influenciar resultados de busca geolocalizados e perceção do utilizador.
- Porta (opcional)
Indicada com “:número” logo após o domínio ou TLD (:8080). Usada quando o serviço corre fora da porta padrão (80 para HTTP, 443 para HTTPS). Essencial para ambientes de testes ou APIs internas. - Caminho (Path to Resource)
A parte após o domínio/TLD que espelha a hierarquia interna do servidor (/blog/git-commands). Em sites estáticos sugere diretórios e ficheiros; em REST/GraphQL, aponta para endpoints lógicos (/api/v1/users). - String de consulta (Query Parameter)
Começa com?e contém pareschave=valorseparados por&. Exemplo:?q=best-git-commands&lang=en. Serve para:- Filtrar ou paginar resultados;
- Transportar parâmetros de tracking (
utm_source); - Personalizar resposta do servidor sem alterar o recurso base.
- Fragmento (Fragment Identifier)
Tudo depois de#(#git_commands_you_should_know). Nunca vai ao servidor — é processado apenas pelo navegador. Direciona para uma âncora interna, manipula navegação SPA (Single‑Page App) ou controla estado cliente‑side.
Quer compreender mais sobre aspectos funcionais de uma URL, quando você efetua uma busca no seu navegador de preferência?
Confira um conteúdo complementar, clicando aqui.