

Conteúdo Atualizado em 14 de agosto de 2025 por felipecferreira, enjoy!
O Hierarchical Reasoning Model (HRM) é uma nova arquitetura recorrente inspirada no cérebro humano que promete dar um salto em raciocínio com poucos dados de treino e baixo custo computacional.
Esta é mais uma revisão de artigos científicos em nosso portal, que visa disponibilizar os avanços na fronteira do conhecimento em Inteligência Artificial de forma simplificada e em nosso idioma.
Você pode acessar o artigo de Wang et al (2025), na íntegra, clicando aqui.
Bom, voltando ao raciocínio, em vez de depender de chain‑of‑thought (CoT), o Hierarchical Reasoning Model (HRM) faz o “trabalho pesado” no espaço latente, em ciclos hierárquicos (daqui o nome) rápidos e lentos, e entrega a resposta em um único forward pass (processamento completo da entrada até a saída em uma única execução do modelo).
Nos testes, um HRM com ~27 milhões de parâmetros treinado com cerca de 1.000 exemplos superou modelos muito maiores em benchmarks como ARC‑AGI e resolveu Sudoku extremo e labirintos 30×30 onde métodos CoT falharam.
Abaixo temos uma imagem retirada diretamente do paper, que compara o HRM com outros modelos (Deepseek R1, Claude 3.7 e GPT o3-mini-high).
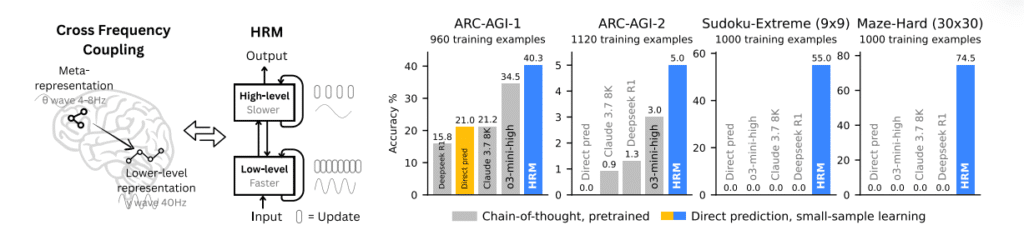
Vale ressaltar que o HRM não foi “acoplado” a um LLM pré-treinado como GPT ou Claude, isto é, ele foi treinado do zero (random initialized) em formato sequence-to-sequence, com seus próprios módulos recorrentes H (alto nível) e L (baixo nível), implementados com blocos Transformer encoder-only.
Sensacional né!?
Vamos ver isso tudo um pouco mais a fundo.
A ideia central no HRM: dois “cérebros” que pensam em ritmos diferentes
O HRM divide o raciocínio em dois módulos recorrentes acoplados:
- Módulo de alto nível (H): faz o planejamento abstrato, atualizando mais devagar.
- Módulo de baixo nível (L): executa cálculos rápidos e detalhados, atualizando muitas vezes até atingir um equilíbrio local.
Esse desenho cria o que os autores chamam de convergência hierárquica: o L (Low) roda várias iterações rápidas até estabilizar; então o H (High) dá um “passo” e reinicializa o L para um novo subciclo.
Isso evita a convergência precoce típica de Redes neurais recorrentes (RNNs) e aumenta a profundidade efetiva de computação sem estourar memória com backpropagation through time.
Resultado: mais “passos de pensamento” efetivos na mesma passada e com estabilidade de treino.
Para treinar, o HRM usa uma aproximação de gradiente em 1 passo (inspirada em Deep Equilibrium Models), o que mantém memória O(1) e dispensa o unroll longo no tempo.
Conceitualmente, o gradiente “salta” para o último estado de cada módulo e propaga a partir dali.
Na prática (principal aspecto pra nós), isso simplifica o código (PyTorch) e é mais plausível biologicamente.
O que o HRM entregou nos benchmarks (com pouquíssimos dados)?
Como já comentei contigo, os autores treinaram o HRM do zero (sem pré‑treino, sem CoT) no formato seq‑to‑seq, achatando grades 2D para sequência de tokens.
Com ~1.000 exemplos por tarefa, o HRM:
- ARC‑AGI‑1/2 (raciocínio indutivo): bateu modelos CoT maiores, mesmo com janelas de contexto bem menores.
- Sudoku‑Extreme (9×9): atingiu quase perfeição com apenas 1.000 exemplos, isto é, um cenário onde baselines diretos (sem CoT) praticamente não andaram.
- Maze‑Hard (30×30): encontrou caminhos ótimos onde métodos CoT ficaram em 0%.
Detalhe importante para (nós) profissionais: o conjunto Sudoku‑Extreme foi selecionado para ser realmente difícil (média de 22 backtracks por quebra‑cabeça, contra 0,45 em conjuntos artesanais recentes).
Ou seja, foi um teste de ponta!
“Pensar, rápido e devagar”: ACT e scaling no tempo de inferência
O HRM incorpora Adaptive Computation Time (ACT) com uma “cabeça” (lógica) de Q‑learning para decidir quando parar de pensar.
Na prática, o modelo aprende a gastar mais passos em problemas difíceis e menos nos fáceis.
Em Sudoku, o ACT manteve pouco compute médio sem perder acurácia versus uma configuração fixa, e ainda permite escalar na inferência: aumentar o limite de passos em produção melhora a precisão sem retreino.
Essa adaptação é ouro para produtização: você regula latência vs. qualidade por política (ex.: “clientes enterprise” ganham Mmax maior em tarefas críticas) e mantém custo sob controle.
Por que isto desafia o paradigma CoT (e o que muda no dia a dia)
Os LLMs não são Turing‑completos e, com profundidade fixa, tendem a bater no teto em tarefas com planejamento e busca.
O CoT ajuda, mas é frágil: depende da ordem das premissas, infla tokens, fica lento e data‑hungry.
O HRM contorna isso ao internalizar o raciocínio com profundidade efetiva variável, guiada por uma hierarquia inspirada no córtex (ritmos lentos/rápidos).
Traduzindo para o trabalho real B2B/B2C:
- Automação analítica e qualidade de decisão: tarefas que exigem backtracking (ex.: reconciliação de dados, rota logística ótima, planejamento com restrições) podem se beneficiar do ACT + profundidade efetiva sem inflar custo de tokens.
- Soluções on‑prem/edge: a memória O(1) no treino e a execução em um único forward pass reduzem exigências de hardware, abrindo espaço para modelos pequenos especializados que resolvem problemas difíceis.
Como o HRM “pensa” por dentro (e o que observar na prática)
Os autores visualizam timestep a timestep e observam padrões intuitivos:
- Labirintos: o modelo tenta múltiplos caminhos, elimina rotas ruins, depois refina a solução.
- Sudoku: comportamento de busca em profundidade com retrocesso (errou, volta, tenta outra), até fechar a grade.
- ARC: sequência de ajustes incrementais no tabuleiro (tipo hill‑climbing), com poucos “desfazes”.
Essa flexibilidade de estratégia por tarefa é um diferencial: o HRM “escolhe a ferramenta certa” para cada problema.
NOTA: Estes gráficos e descrições aparecem na seção de visualizações do paper.
Quando o HRM faz sentido para você (e quando não)?
Faz sentido quando você precisa de:
- Raciocínio simbólico/algorítmico com pouco dado rotulado (≈1.000 exemplos).
- Controle de compute/latência por amostra (ACT).
- Respostas diretas sem depender de longos CoTs que encarecem e variam demais.
Pode não ser a melhor troca quando:
- O problema é puramente gerativo (copy, narrativa, tone of voice) onde CoT longos ajudam no estilo tanto quanto no raciocínio.
- Já existe infra otimizada para LLMs grandes com tool use e você não enfrenta gargalos de latência/custo nem erros de decomposição em CoT.
Boas práticas para experimentar HRM
Mesmo sem ter o código do HRM no seu stack agora, dá para absorver princípios:
- Profundidade efetiva sob demanda: em tarefas difíceis, faça “mais passos” antes de responder. Hoje, simule com auto‑refine (ex.: draft → critique → revise) e pare cedo quando a confiança estiver alta. Isso espelha o ACT.
- Raciocínio no latente: reduza CoT verboso. Use raciocínio estruturado interno (ex.: scratchpad privado + verificação de consistência) e decodificação direta do resultado final.
- Currículo de dificuldades: o Sudoku‑Extreme dos autores mostra o valor de dados realmente desafiadores. Se seu dataset é fácil, gere variantes “duras” (restrições adicionais, instâncias limite).
- Avalie com métricas “de caminho ótimo”: em problemas de busca/planejamento, exija otimalidade (não apenas validade). É o que eles fizeram nos labirintos.
Conclusões
O HRM sugere uma mudança de eixo: do CoT textual para computação hierárquica latente, com profundidade adaptativa e eficiência de treino.
Em números, um modelo pequeno (~27M) e pouco dado (~1.000 exemplos) derrubou paredes que pareciam “coisa de modelos gigantes”.
Para quem precisa de raciocínio confiável, latência controlável e custos sob medida, vale acompanhar de perto — e, desde já, importar suas ideias para o seu pipeline.
Não Ignore IA, e se quiser ficar na fronteira do desenvolvimento, novidades e aplicações práticas de mercado, cola aqui.