


Você já imaginou treinar um sistema de inteligência artificial sem precisar rodar dezenas de milhares de execuções?
Pois é exatamente essa a proposta do Genetic-Pareto Prompt Optimizer (GEPA), um novo otimizador de prompts que está dando o que falar na comunidade de IA.
A pesquisa foi conduzida por um consórcio de universidades e empresas como UC Berkeley, Stanford, MIT e Databricks, e mostra que usar linguagem natural para refletir sobre erros e acertos pode ser mais eficiente do que o tradicional treinamento por Reforço.
Você pode acessar o paper na íntegra, clicando aqui.
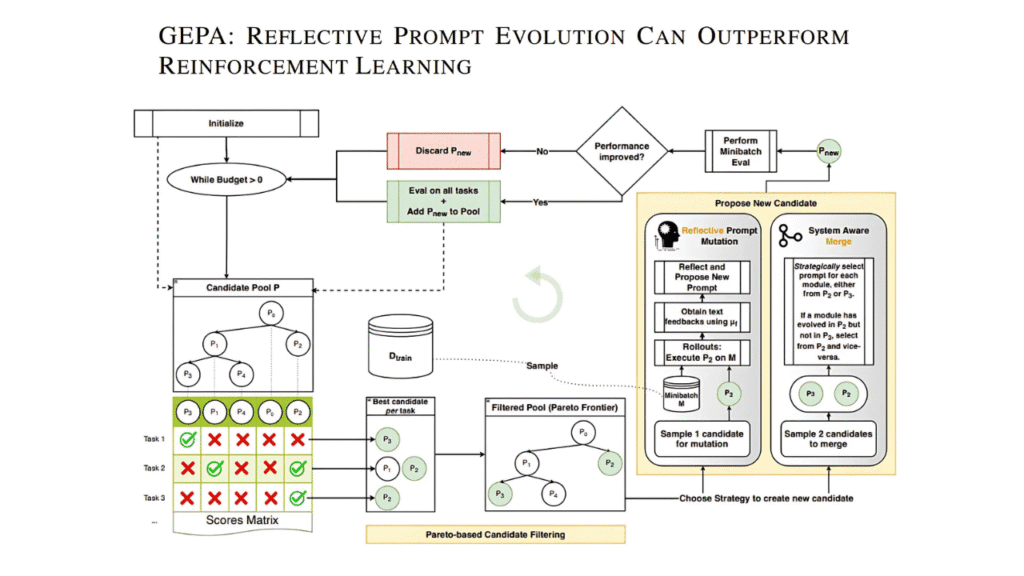
O que é o GEPA e por que ele é diferente?
GEPA é a sigla para Genetic-Pareto Prompt Optimizer.
Em vez de depender de recompensas numéricas e técnicas de reinforcement learning como o GRPO, o GEPA adota uma abordagem inspirada em evolução genética e reflexão textual.
Vaamos Traduzir: ele pega o histórico de tentativas de um sistema (incluindo raciocínios e chamadas de ferramentas), e reflete em linguagem natural sobre o que deu certo ou errado.
Com base nessa autoanálise, propõe novas versões de prompts mais eficazes, e o faz de maneira iterativa, como em um processo evolutivo.
A cereja do bolo?!
GEPA faz isso mantendo um conjunto de candidatas de alto desempenho, a chamada fronteira de Pareto, garantindo diversidade de estratégias e evitando cair em armadilhas de melhoria local.
Simplesmente sensacional!!
Resultados impressionantes em benchmarks
A equipe por trás do GEPA testou sua abordagem em quatro benchmarks distintos:
- HotpotQA (raciocínio multi-hop)
- IFBench (instruções com múltiplas restrições)
- HoVer (verificação factual)
- PUPA (reescrita com preservação de privacidade)
A imagem abaixo mostra a performance dos diferentes métodos de otimização de prompts no benchmark HotpotQA (à esquerda) e HoVer (à direita), utilizando o modelo Qwen3 8B.
A linha azul representa o GEPA, enquanto as linhas verde e laranja indicam os otimizadores MIPROv2 e GRPO, respectivamente.

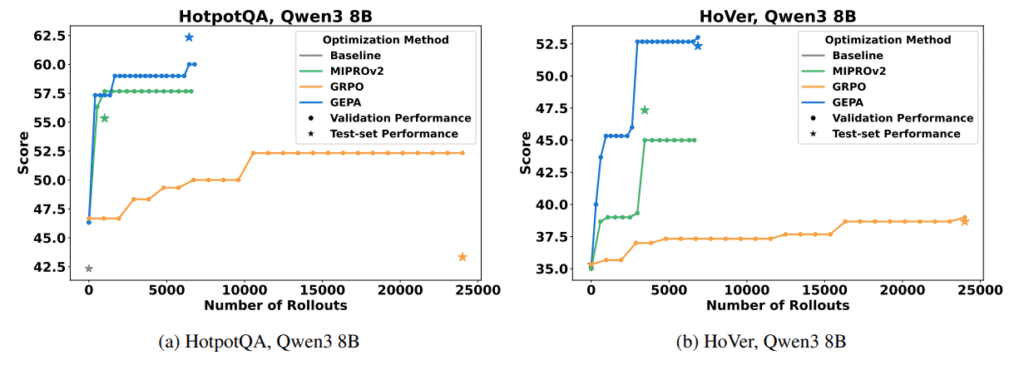
O gráfico deixa claro que o GEPA atinge resultados superiores com muito menos rollouts, superando com folga os concorrentes tanto na validação quanto nos testes.
Destaque para a escalada rápida de desempenho do GEPA nas primeiras interações, enquanto os demais métodos estagnam mesmo após milhares de execuções adicionais.
Em todos os casos, o GEPA superou tanto o GRPO (Reinforcement Learning com 24.000 rollouts) quanto o melhor otimizador anterior, o MIPROv2.
Destaques dos resultados:
- Obteve até 20% de vantagem sobre o GRPO, utilizando até 35x menos rollouts.
- Superou o MIPROv2 em todos os testes e com ambos os modelos avaliados (Qwen3 8B e GPT‑4.1 Mini).
- Produziu prompts com mais desempenho e até 9x mais curtos, o que reduz o custo de execução e latência.
Como o GEPA funciona na prática?
O GEPA segue uma lógica evolutiva:
- Executa o sistema com prompts iniciais, e avalia os resultados.
- Reflete em linguagem natural sobre o que funcionou ou falhou em cada etapa (inclusive utilizando mensagens de erro de compiladores e outputs de ferramentas).
- Gera uma nova versão do prompt com base nesses aprendizados.
- Avalia a nova versão e a mantém no “pool” de candidatos apenas se houver melhora mensurável.
- Seleciona candidatos de destaque com base em múltiplos critérios, formando um conjunto diversificado de estratégias vencedoras (a fronteira de Pareto).
Esse processo continua iterativamente até que o orçamento de execuções (rollouts) se esgote.
Exemplo aplicado: melhorando um sistema de resposta multi-hop
Imagine um sistema de Q&A (Question > Answering) que responde perguntas complexas com base em múltiplos documentos.
O prompt original apenas instruía:
“Dado o campo ‘pergunta’ e o ‘resumo 1’, gere um novo ‘query’.”
Já a versão otimizada pelo GEPA detalha o que é cada campo, quais conexões devem ser inferidas, o que evitar, e até fornece estratégias práticas.
Isso permitiu ao sistema buscar informações complementares com precisão, em vez de apenas repetir a pergunta original.
GEPA: Mais leve, mais rápido e mais barato
Além de mais eficaz, o GEPA gerou prompts até 9x menores que os do MIPROv2, o que significa:
- Redução de custo em APIs de LLMs (menos tokens enviados)
- Respostas mais rápidas
- Menos complexidade para debugging e manutenção de sistemas
Isso tem implicações práticas imensas para startups e empresas que operam sistemas baseados em LLMs sob restrição de orçamento ou tempo de resposta.
O que isso muda para empresas que usam IA?
Para empresas que treinam agentes baseados em LLMs, o GEPA representa uma alternativa altamente vantajosa:
- Não depende de acesso ao peso dos modelos, o que é útil para APIs fechadas como OpenAI ou Claude.
- Pode otimizar sistemas compostos com múltiplos módulos, como pipelines de RAG, chatbots, agentes de atendimento, ferramentas de código e mais.
- Oferece adaptação em tempo de inferência, o que abre portas para otimizações mesmo sem necessidade de treinamento completo.
O que nos Aguardo o Futuro com o GEPA?
A pesquisa sugere que o GEPA também pode ser utilizado como uma técnica de search em tempo real, como em tarefas de geração de código.
Em testes com GPT-4o, o GEPA conseguiu gerar kernels CUDA e NPU com desempenho superior a 70% de utilização vetorial, isto é, algo que agentes tradicionais não alcançaram, mesmo com múltiplas tentativas.
A evolução orientada por reflexão e diversidade parece ser uma chave promissora para o futuro da IA.
Ao invés de somente aprender com números, o GEPA nos mostra como modelos podem aprender com… palavras.
Conclusões: um passo adiante na era dos agentes otimizáveis
O GEPA marca uma mudança de paradigma na forma como sistemas de IA são ajustados e otimizados.
Ele não apenas alcança melhores resultados, como também faz isso com menor custo computacional (olhar atento pra eficiência de automações aqui), menos tempo e com prompts mais claros.
Se você trabalha com agentes autônomos, sistemas de atendimento, pipelines de NLP ou automação de tarefas com LLMs, vale a pena estudar a fundo essa abordagem.
Lembrando, o link do paper tá logo no início desta revisão!
Não Ignore IA, e se quiser ficar na fronteira do desenvolvimento, novidades e aplicações práticas de mercado, cola aqui.
S2