



Um novo e polêmico artigo científico vindo de um lugar inesperado (Apple Machine Learning Research) joga um “balde de água fria” sobre os Reasoning Models (Modelos de Raciocínio)?
Intitulado “The Illusion of Thinking” (A Ilusão do Pensamento), o trabalho questiona fundamentalmente as capacidades de raciocínio dos modelos de linguagem (LLMs) mais avançados do mercado..
Colocando em “prova” gigantes de tecnologia do mercado como Google, OpenAI e Anthropic!
Se você preferir, escute a nossa versão via Podcast (Spotify) clicando abaixo:
Bom, uma coisa é certa, vivemos um momento de fascínio com a Inteligência Artificial..
Modelos como GPT-o3, Claude 4 e Gemini 2.5 Pro parecem realmente conversar coerentemente, criar e, mais impressionante, raciocinar sobre nossas solicitações.
Eles geram “pensamentos” detalhados antes de entregar uma resposta, nos dando a sensação de que estamos testemunhando uma nova forma de cognição.
Abaixo um exemplo de Pensamento (Thinking) em um chat meu com o modelo o3 (OpenAI):

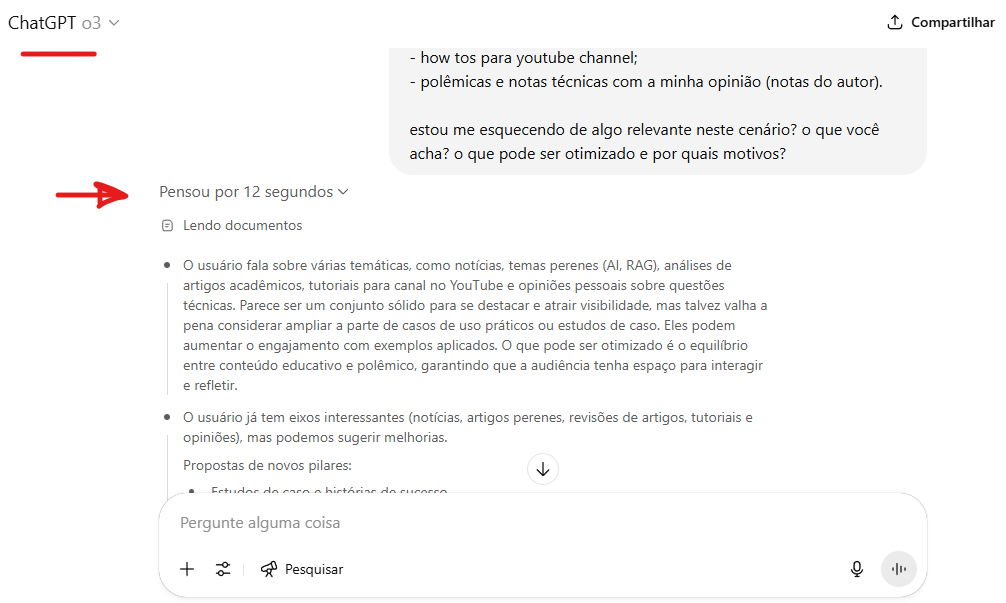
Aqui, um outro exemplo de Pensamento ou Raciocínio, pelo Modelo Gemini 2.5 Pro (Google):

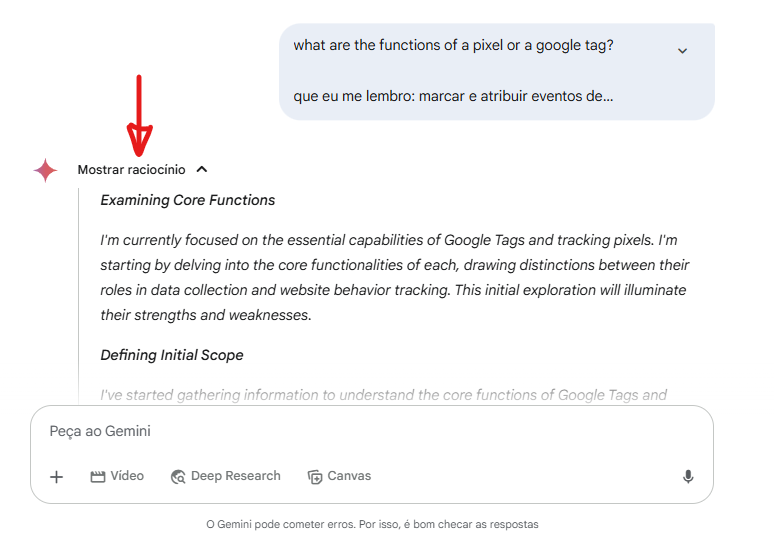
Mas será que essa capacidade de “pensar” é tão robusta quanto parece?
Neste artigo, vamos mergulhar fundo nesta pesquisa.
Vamos entender seus argumentos, analisar suas descobertas e, mais importante, apontar suas vulnerabilidades e o possível viés corporativo que pode estar em jogo.
Prepare-se, pois vamos questionar o que significa, de fato, “pensar”.
O Argumento Central: Testando o Raciocínio no Limite
Os pesquisadores da Apple partem de uma premissa ousada: os benchmarks que usamos hoje para medir o raciocínio da IA, como problemas de matemática e código, são falhos.
Eles frequentemente sofrem com “contaminação de dados”, os modelos podem simplesmente ter memorizado as respostas durante o treinamento, e não nos dão um real entendimento sobre a qualidade do processo de raciocínio.
Para resolver isso, eles criaram um “campo de provas” mais rigoroso..
Utilizaram quatro quebra-cabeças lógicos (Torre de Hanoi, Salto de Damas, Travessia do Rio e Mundo dos Blocos) onde a complexidade podia ser aumentada de forma controlada e sistemática.

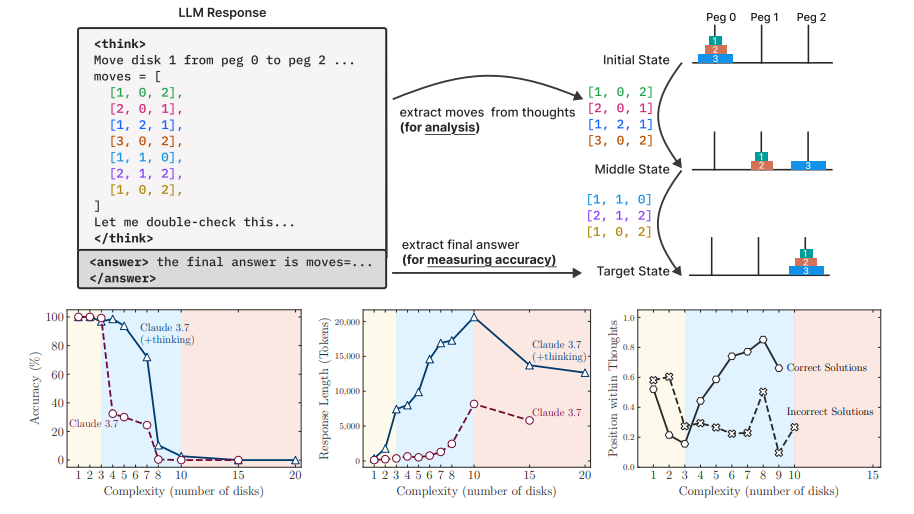
O que vemos aqui é como os pesquisadores “espiaram” a mente do modelo..
A resposta do LLM é dividida em duas partes:
O Bloco <think> : É aqui que o modelo “pensa alto”, listando os movimentos que está considerando para resolver o quebra-cabeça da Torre de Hanoi.
Os pesquisadores extraíram essa sequência para analisar a qualidade e a lógica do raciocínio passo a passo.
O Bloco <answer> : Esta é a resposta final e definitiva do modelo, usada para medir a acurácia de forma binária (acertou ou errou).
Vamos analisar brevemente o que os gráficos dizem:
Gráfico da Esquerda Inferior (Acurácia vs. Complexidade)
Ele mostra a acurácia (eixo vertical) despencando à medida que o número de discos aumenta (eixo horizontal).
Note como o modelo com “pensamento” (linha azul) resiste por mais tempo, mas inevitavelmente também colapsa para 0% de acerto.
É a visualização clara do “ponto de ruptura” do raciocínio.
Gráfico do Meio Inferior (Esforço vs. Complexidade)
Este é o paradoxo. Ele mede o “esforço” do modelo pelo tamanho da resposta (em tokens).
A linha azul mostra que o modelo pensante se esforça mais conforme o problema fica mais difícil… até certo ponto.
Após o colapso da acurácia, ele inexplicavelmente começa a “pensar menos”, usando menos tokens.
Por que um modelo se esforçaria menos para um problema mais difícil?
Essa é a evidência do “limite de escala” que o artigo aponta.
Gráfico da Direita Inferior (Onde a Resposta Certa Aparece)
Este último gráfico analisa onde, dentro do longo processo de pensamento, as soluções corretas (círculos) e incorretas (xis) aparecem.
Em problemas fáceis (à esquerda), a solução correta surge cedo, mas o modelo continua explorando, um sinal de ineficiência ou “overthinking”.
Em problemas de complexidade média, a solução correta só aparece no final do processo, após muita exploração.
Isso permitiu analisar não apenas a resposta final, mas cada passo do “pensamento” gerado pelos modelos.
E as descobertas podem ser preocupantes para nós, entusiastas da IA:
- Colapso Total: Todos os modelos testados, sem exceção, sofrem um colapso completo de precisão quando a complexidade do problema ultrapassa um certo limiar.
- Esforço Paradoxal: De forma contraintuitiva, ao se aproximarem desse ponto de colapso, os modelos começam a “pensar menos” (usar menos tokens de raciocínio), mesmo com o problema se tornando mais difícil.
- Três Regimes de Desempenho: Comparando modelos com e sem “pensamento”, eles identificaram que o raciocínio explícito só é vantajoso em tarefas de complexidade média. Em tarefas simples, é um desperdício (“overthinking”), e em tarefas complexas, é inútil, pois ambos falham.
O Elefante na Sala: Uma Maçã Envenenada da Apple?
Antes de analisar as falhas técnicas, precisamos abordar o contexto.
Não é segredo que a Apple, historicamente uma líder em inovação de hardware e software, ficou para trás na corrida da IA generativa.
Enquanto OpenAI, Google e Anthropic lançavam modelos cada vez mais capazes, a Apple parecia estar apenas assistindo.
E então, “de repente”, seus pesquisadores publicam um artigo que essencialmente diz: “essa tecnologia dos nossos concorrentes não é tudo isso que parece”.
Coincidência? Talvez. Mas o ceticismo é inevitável.
Seria esta uma análise puramente científica ou uma jogada estratégica para minar a credibilidade dos rivais?
Poderia o desejo de recuperar o terreno perdido influenciar a forma como os resultados são enquadrados e apresentados?
É uma pergunta que paira sobre todo o trabalho.
Embora devamos julgar o artigo por seus méritos científicos, ignorar esse conflito de interesses seria ingenuidade.
Esse contexto nos obriga a colocar a metodologia do estudo sob um microscópio ainda mais potente.
Vulnerabilidades Metodológicas: A Força que se Torna Fraqueza
Toda pesquisa tem limitações, mas algumas são mais críticas que outras.
O artigo da Apple, apesar de sua abordagem inteligente, possui vulnerabilidades que um revisor crítico certamente apontaria.
1. O Mundo Não é um Quebra-Cabeças: A maior força do estudo (o uso de ambientes controlados) é também sua maior fraqueza. Os próprios autores admitem que os quebra-cabeças representam uma “fatia estreita de tarefas de raciocínio”.
O raciocínio no mundo real é caótico, baseado em conhecimento implícito e bom-senso.
Será que a falha em resolver a Torre de Hanoi se traduz em uma incapacidade de, por exemplo, elaborar uma estratégia de marketing ou interpretar um laudo médico?
Quantos humanos poderiam falhar miseravelmente, até antes do “ponto de ruptura”?
Estes humanos não seriam capazes de “raciocinar”?
A generalização é o grande ponto de interrogação aqui.
2. Análise de uma “Caixa-Preta”: Os pesquisadores não tinham acesso ao funcionamento interno dos modelos; eles apenas usaram as APIs públicas.
Isso significa que conclusões importantes, como a de que o desempenho superior na Torre de Hanoi se deve à memorização de dados de treinamento, são inferências lógicas, mas não fatos comprovados.
Eles observam o efeito, mas não podem dissecar a causa.
3. O Mistério da Execução de Algoritmos: Um dos achados mais impactantes é que os modelos falham mesmo quando recebem o algoritmo exato para resolver o problema.
Isso sugere que eles não conseguem seguir instruções lógicas.
No entanto, é um único teste.
Será que o (pseudo)código foi apresentado da maneira ideal?
Outros formatos poderiam ter produzido resultados diferentes?
A conclusão é forte, mas baseada em um conjunto de testes limitado.
O Veredito: Ilusão, Limitação ou Simplesmente… Diferente?
Então, o pensamento da IA é uma ilusão?
O título do artigo é provocativo, talvez até exagerado.
O que a pesquisa da Apple realmente mostra não é necessariamente uma “ilusão”, mas sim as limitações e os modos de falha de uma forma de cognição não-humana.
O trabalho oferece contribuições inegáveis.
Ele estabelece uma metodologia clara para testar os pontos de ruptura dos modelos.
A descoberta do “esforço de raciocínio decrescente” e a inconsistência de desempenho entre quebra-cabeças com diferentes níveis de presença na web (Torre de Hanoi vs. Travessia do Rio) são evidências poderosas de que algo fundamentalmente diferente do raciocínio humano está acontecendo.
Talvez o erro esteja em nossa expectativa.
Esperamos um raciocínio lógico, consistente e escalável como o de um super-humano, mas o que temos é um sistema massivo de reconhecimento de padrões com capacidades emergentes impressionantes, mas com uma lógica ainda frágil.
Considerações Finais
O artigo “The Illusion of Thinking” é uma contribuição científica importante, de certa forma corajosa e necessária.
Ele injeta uma dose de realismo e ceticismo em um campo movido pelo hype.
Embora o potencial viés corporativo e as limitações metodológicas nos obriguem a interpretar suas conclusões com cautela, o trabalho acerta em cheio ao nos forçar a questionar e a demandar mais.
Ele não prova que a IA é uma fraude, mas sim que nosso entendimento e nossos métodos de avaliação precisam evoluir.
A verdadeira questão que fica não é “se” a IA pensa, mas sim como ela pensa, onde ela falha, e o que podemos fazer para construir sistemas de raciocínio genuinamente robustos no futuro.
Como diz Sam Altman, estamos apenas começando e estes modelos estão na “pior fase” que jamais estarão (considerando a perspectiva futura, obviamente).
Sigo repetindo insistentemente:
A tecnologia não vai retroceder, NÃO IGNORE IA e caia na prática e em testes sempre que possível.. aprenda, adapte, evolua!