

Conteúdo Atualizado em 27 de abril de 2025 por felipecferreira, enjoy!
Introdução ao Machine Learning (ML)
Machine Learning (ML), ou Aprendizado de Máquina, é um subcampo da Inteligência Artificial (IA) que capacita sistemas computacionais a aprenderem e melhorarem a partir de experiências anteriores, sem a necessidade de programação explícita para cada tarefa.
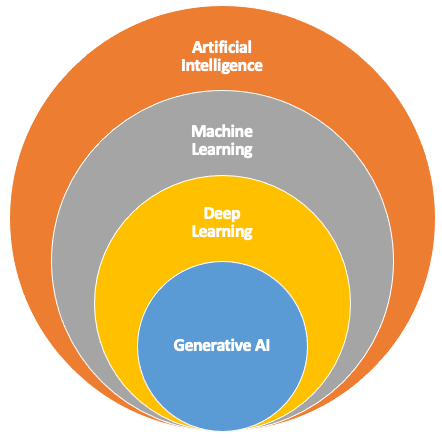
Dentro do “campo” da Inteligência Artificial, temos outros grandes departamentos como o dos sistemas que trabalham com ML, o Deep Learning (Aprendizado Profundo), e aí sim, IAs Generativas (como o ChatGPT ou Gemini).
Não sabe ainda o que é Inteligência Artificial? Clique Aqui.
Vamos analisar um pouco melhor e explicar alguns dos principais aspectos relacionados a imagem acima.
Como podemos ver, o Deep Learning (DL) é uma subcategoria de ML que utiliza redes neurais artificiais profundas, com muitas camadas, para modelar e entender padrões complexos nos dados (basicamente com recursos avançados de matemática).
A “profundidade” dessas redes (ou seja, o número de camadas) permite que os modelos de DL aprendam representações de dados em múltiplos níveis de abstração, tornando-os muito eficazes em tarefas como reconhecimento de imagem, processamento de linguagem natural (NLP) e mais.
Por último (nesta nossa análise simplificada), a IA Generativa, como os modelos GPT (Generative Pre-trained Transformer) e Gemini, é justamente uma aplicação de DL que se concentra em gerar novos dados (como texto, imagens ou áudio) a partir de padrões aprendidos.
Esses modelos são baseados em arquiteturas de redes neurais profundas, especificamente aquelas que utilizam mecanismos como transformers para processar grandes quantidades de dados e gerar saídas que parecem ter sido criadas por humanos.
Se ficou um pouco confuso, fique tranquilo(a), principalmente se estes são os seus primeiros contatos com a temática.
A atitude de estar lendo isto neste momento, demonstra que você já faz parte do 1% que compreendeu a importância de se atualizar e saber mais sobre o universo da IA.
Então respira fundo e vem comigo..
Vamos ver um pouco de história..
Breve Histórico sobre ML
O conceito de Machine Learning remonta às décadas de 1940 e 1950, com a criação dos primeiros algoritmos que imitavam o processo de aprendizagem humana.
Um marco importante foi a invenção do Perceptron, em 1957, por Frank Rosenblatt, considerado uma das primeiras redes neurais artificiais.

Nas décadas seguintes, a evolução dos computadores e o aumento do poder computacional permitiram avanços significativos na área.
Nos anos 1990, o surgimento de técnicas como Support Vector Machines (SVM) e Árvores de Decisão ajudou a solidificar o campo.
Nos anos 2000, com o crescimento exponencial de dados e o desenvolvimento de novas técnicas de processamento, o ML tornou-se fundamental para aplicações como reconhecimento de fala, visão computacional e sistemas de recomendação.
Hoje, o ML é uma tecnologia central em inovações como carros autônomos, assistentes virtuais e sistemas de previsão.
Vamos agora analisar as principais categorias de aprendizado..
Categorias de Aprendizado em Machine Learning
Aprendizado Supervisionado
O Aprendizado Supervisionado é a abordagem mais comum em Machine Learning e envolve a construção de modelos preditivos com base em dados rotulados (rótulo basicamente indica que cada dado de entrada “input” terá um dado de saída correspondente “output”).
O objetivo do algoritmo é aprender a mapear essas entradas para as saídas de maneira precisa, de modo que, quando apresentado a novos dados não vistos, ele possa prever as saídas corretas.
Vamos conferir a imagem abaixo:
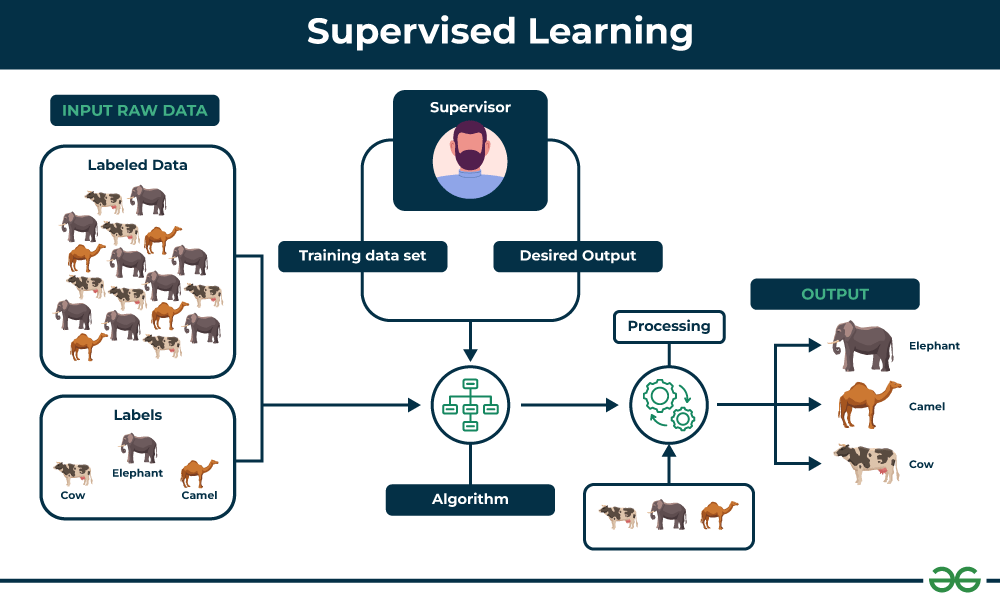
Existem diferentes formas de explicar a figura, vou tentar simplificar.
O nome “supervisionado” é atribuído pois os dados que serão utilizados para o treinamento do modelo foram previamente organizados (label – rotulados), contendo a correta classificação ou resposta.
Esses dados são geralmente separados em uma regra 70/30, onde 70% são utilizados para o treinamento do modelo e 30% para seu teste (os percentuais vão variar caso a caso).
Na figura, os dados possuem rótulos de imagens como Vaca, Elefante e Camelo.
Estes dados são então utilizados para “rodar” o algoritmo, que também terá o treinamento supervisionado, podendo conter ajustes para a saída desejada (Desired Output).
Após o processamento, o modelo é testado, onde poderíamos (como no exemplo), apresentar imagens de animais e solicitar que ele responda se o que ele “vê” é uma Vaca, Elefante ou Camelo.
Um outro exemplo prático é um modelo de regressão linear (tipo do algoritmo) que prevê o preço de uma casa com base em características como área, número de quartos, vaga de garagem, localização (e etc.).
Neste exemplo, o modelo precisa ser treinado em uma ampla base de dados que já foram rotulados com as características de diversos imóveis em função de seus preços.
Durante o treinamento, o modelo ajusta seus parâmetros para minimizar a diferença entre os preços previstos e os reais presentes no conjunto de treinamento.
Assim, ao chegar um novo imóvel na imobiliária, por exemplo, o modelo pode ser utilizado para comparar o valor de venda, analisar viabilidade, margens de lucro (comissionamento) entre outros.
Aprendizado Não Supervisionado
O Aprendizado Não Supervisionado, por outro lado, lida com dados que não possuem rótulos predefinidos.
Nesse caso, o algoritmo é responsável por identificar padrões ou estruturas inerentes aos dados sem qualquer orientação prévia.
Esse processo de descoberta é especialmente útil em situações onde os rótulos não estão disponíveis ou seriam muito caros para se obter.
Vamos conferir a imagem abaixo, mantendo o exemplo com os animais:
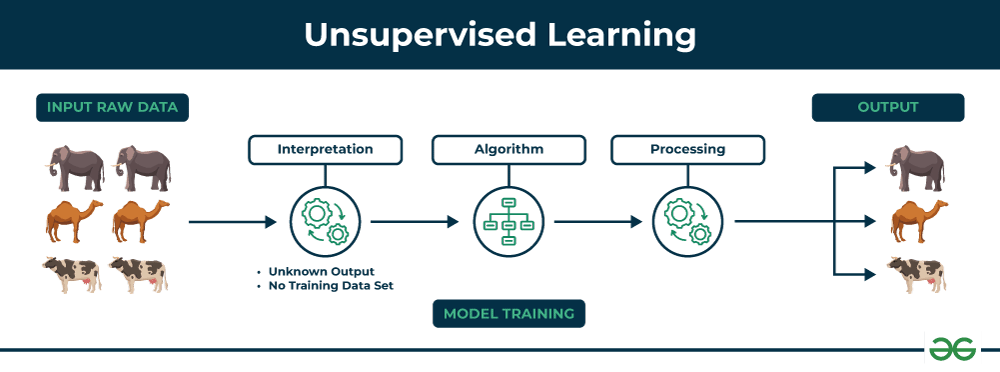
O processo começa com um conjunto de dados brutos (input raw data – imagens de animais), que não têm nenhum rótulo associado.
Os dados apresentados incluem imagens de elefantes, camelos e vacas, mas o sistema não tem conhecimento prévio de que esses são os animais presentes.
O algoritmo analisa esses dados de entrada e tenta identificar similaridades ou padrões entre eles.
Neste estágio, o sistema começa a perceber que algumas das imagens têm características semelhantes, mesmo sem saber o que essas características representam.
O algoritmo de aprendizado não supervisionado, como o K-means ou outro método de clustering (agrupamentos), processa os dados para agrupar as imagens com base em suas características intrínsecas, como forma, tamanho, cor, etc.
No exemplo, o algoritmo pode identificar que algumas imagens têm orelhas grandes e trombas (elefantes), enquanto outras têm duas corcovas (camelos), e assim por diante.
O resultado final do processo é que o algoritmo agrupa as imagens de maneira lógica: elefantes são agrupados juntos, camelos em outro grupo, e vacas em outro.
Importante destacar que, embora o algoritmo tenha identificado corretamente os grupos, ele ainda não sabe os nomes desses grupos (elefantes, camelos, vacas).
Apenas que as imagens dentro de cada grupo compartilham características similares.
Pegou a lógica?
Vamos fechar com outro exemplo prático.
Imagine uma BIG empresa do setor do Varejo, por exemplo..
Esta empresa deseja segmentar a sua base de clientes (data) para direcionar campanhas de marketing de forma mais eficaz, mas não tem informações claras sobre quem são os melhores clientes para determinadas linhas de produto (diferentes).
Utilizando um algoritmo de clustering, como o K-means, a empresa pode agrupar seus clientes em segmentos baseados em comportamentos de compra, frequência de visitas e valor gasto, mesmo sem rótulos pré-definidos.
Cada grupo identificado pelo algoritmo pode representar um segmento de mercado distinto, como compradores frequentes, “loucos por cupons/descontos”, compradores noturnos, entre outros..
Desta forma a empresa pode criar estratégias de marketing mais direcionadas.
Em resumo, o aprendizado não supervisionado é uma poderosa ferramenta de descoberta em Machine Learning, permitindo a identificação de padrões ocultos e a segmentação de dados de forma intuitiva, sem a necessidade de rótulos prévios.
Aprendizado por Reforço (Reinforcement Learning)
O Aprendizado por Reforço é uma abordagem inspirada em como os seres vivos aprendem com o ambiente.
Nesse paradigma, um agente (algoritmo ou robô) interage com um ambiente e aprende a tomar decisões sequenciais com o objetivo de maximizar uma recompensa cumulativa.
O agente recebe feedback na forma de recompensas ou penalidades, com base em suas ações, e ajusta suas estratégias para melhorar seu desempenho ao longo do tempo.
Se você pensou em algo como o adestramento de um cão, você está certo(a)!
Mas para contextualizarmos e entendermos melhor, vamos a uma nova imagem abaixo:
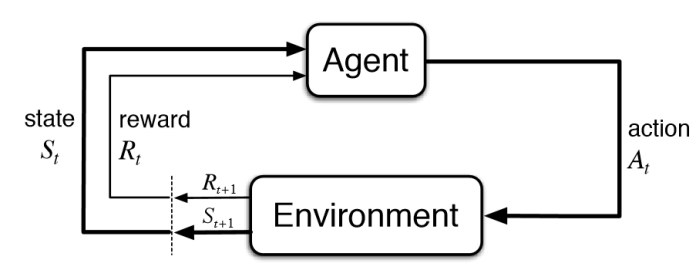
Primeiro vamos entender a imagem, é um raciocínio super simples..
Estado Inicial (State, 𝑆𝑡): O ciclo começa com o agente em um determinado estado do ambiente (situação atual).
Ação (Action, 𝐴𝑡): O agente decide realizar uma ação específica. Esta ação pode ser qualquer coisa que afete o ambiente, como mover-se para uma direção em um labirinto, alterar a velocidade em um carro autônomo, ou escolher uma resposta em um chatbot.
Ambiente (Environment): Após a ação do agente, o ambiente reage e muda de estado. Por exemplo, se o agente decidir mover-se para a direita, o ambiente mudará para refletir a nova posição do agente.
Recompensa (Reward, 𝑅𝑡): O ambiente também fornece uma recompensa ao agente com base na ação que ele tomou. Essa recompensa pode ser positiva (se a ação foi benéfica) ou negativa (se a ação foi prejudicial). O objetivo do agente é maximizar a soma das recompensas ao longo do tempo.
Novo Estado (Next State, 𝑆𝑡+1): O agente então observa o novo estado do ambiente após sua ação e recebe a recompensa associada. Este novo estado será o ponto de partida para a próxima decisão do agente.
Repetição do Ciclo: Esse ciclo de decisão e feedback continua, com o agente ajustando suas ações com base nas recompensas recebidas e na evolução do estado do ambiente.
Agora, para não perdermos o “fio”, vamos retornar ao exemplo do modelo que seria responsável por identificar se a imagem era de um Camelo, Vaca ou Elefante..
Mas agora utilizando a Aprendizagem por Reforço..

Estado Inicial (State, 𝑆𝑡): O robô começa observando uma imagem no ambiente, por exemplo, uma imagem que pode ser de um elefante, camelo ou vaca, mas ele ainda não sabe qual.
Ação (Action, 𝐴𝑡): O robô pode “escolher” classificar a imagem como “Elefante”, “Camelo” ou “Vaca”.
Ambiente (Environment): Dependendo da escolha do robô, o ambiente fornecerá uma nova imagem para classificação e, ao mesmo tempo, dará feedback sobre a escolha anterior.
Recompensa (Reward, 𝑅𝑡): Se o robô classificar corretamente a imagem, ele receberá uma recompensa positiva (por exemplo, +1 ponto score). Se ele errar, receberá uma recompensa negativa (por exemplo, -1 ponto).
Novo Estado (Next State, 𝑆𝑡+1): O robô agora vê a próxima imagem e o ciclo se repete. Ele ajusta suas decisões futuras com base nas recompensas passadas para melhorar sua precisão ao longo do tempo.
Agora que demos mais este passo importante na compreensão de Machine Learning, vamos ver um pouco sobre esses algoritmos..
Principais Algoritmos de Machine Learning
Machine Learning abrange uma variedade de algoritmos, cada um com seus próprios métodos e aplicações.
Esses algoritmos são ferramentas fundamentais para transformar dados em insights acionáveis, capacitando sistemas a fazer previsões, identificar padrões e tomar decisões com base em informações complexas.
Abaixo, exploramos alguns dos algoritmos mais importantes e amplamente utilizados em Machine Learning.
Algoritmos de Regressão
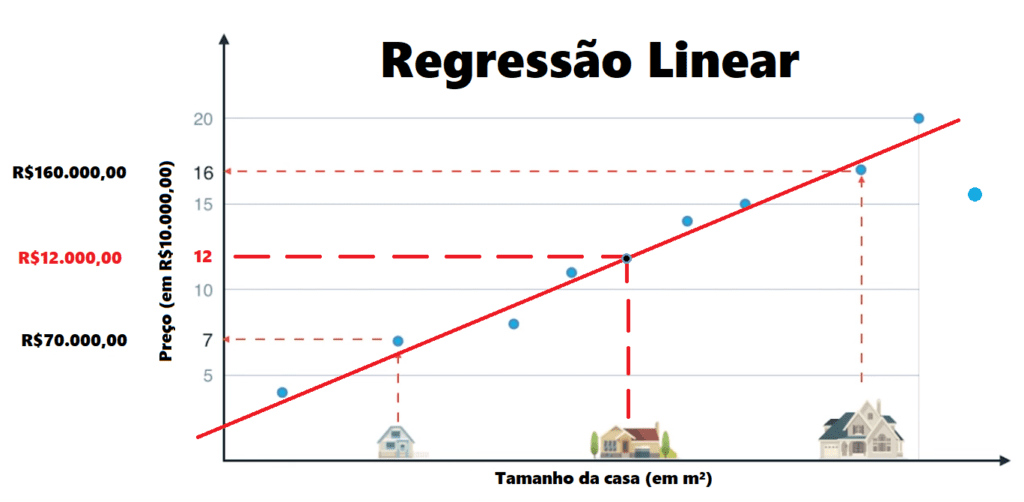
Regressão Linear
A Regressão Linear é um dos algoritmos mais simples e amplamente utilizados em Machine Learning, especialmente em problemas de previsão contínua.
Seu objetivo é modelar a relação entre uma variável dependente (o que se deseja prever) e uma ou mais variáveis independentes (os fatores que influenciam a previsão).
O modelo de regressão linear tenta encontrar a melhor linha reta (ou plano, em casos multivariados) que minimize a diferença entre as previsões do modelo e os valores reais.
Exemplo Prático: Como já mencionamos, a previsão do preço de imóveis com base em variáveis como metragem quadrada, localização, número de quartos (suítes), vagas na garagem etc.
Regressão Logística
Embora seu nome sugira uma semelhança com a Regressão Linear, a Regressão Logística é usada principalmente para problemas de classificação binária, onde o objetivo é prever a probabilidade de uma variável dependente pertencer a uma das duas categorias.
Ao invés de modelar uma relação linear direta, a regressão logística aplica a função logística (ou sigmoide) para transformar as previsões em probabilidades.
Exemplo Prático: mantendo no exemplo do setor imobiliário, podemos ter um modelo que calcule a probabilidade de venda de um imóvel, como “Sim” (imóvel com alta chance de venda) ou “Não” (imóvel com baixa chance de venda).
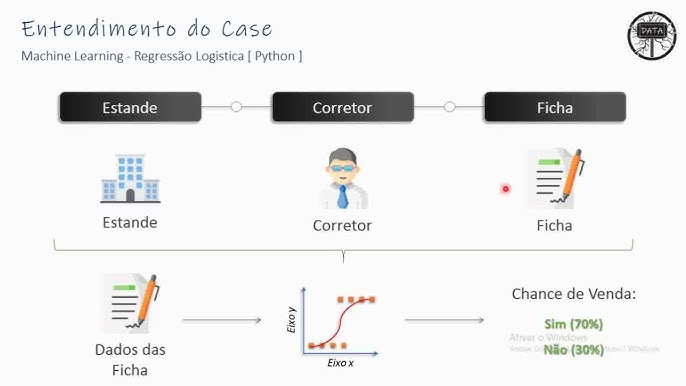
O resultado é uma probabilidade entre 0 (Não) e 1 (Sim), que pode ser convertida em uma classificação (imóvel com chance ou sem chance de venda) usando um limiar (por exemplo, se a probabilidade for maior que 0.5 – ou 50%, classificamos como “Sim”).
Concluindo, a regressão linear é usada para problemas de regressão, onde a variável de saída é contínua (numérica).
A regressão logística é usada para problemas de classificação, onde a variável de saída é categórica (classes ou categorias).
Algoritmos Baseados em Árvores
Árvores de Decisão
As Árvores de Decisão são algoritmos poderosos e interpretáveis, que dividem os dados em subconjuntos baseados em perguntas sequenciais.
Cada nó da árvore representa uma decisão baseada em uma característica, e os ramos são os possíveis resultados dessa decisão, até chegar a uma folha, que dá a previsão final.
As Árvores de Decisão são altamente flexíveis e podem ser usadas tanto para regressão quanto para classificação.
Achei uma figura ilustrativa excelente, com o exemplo de decisão sobre “ir ou não para a aula”.
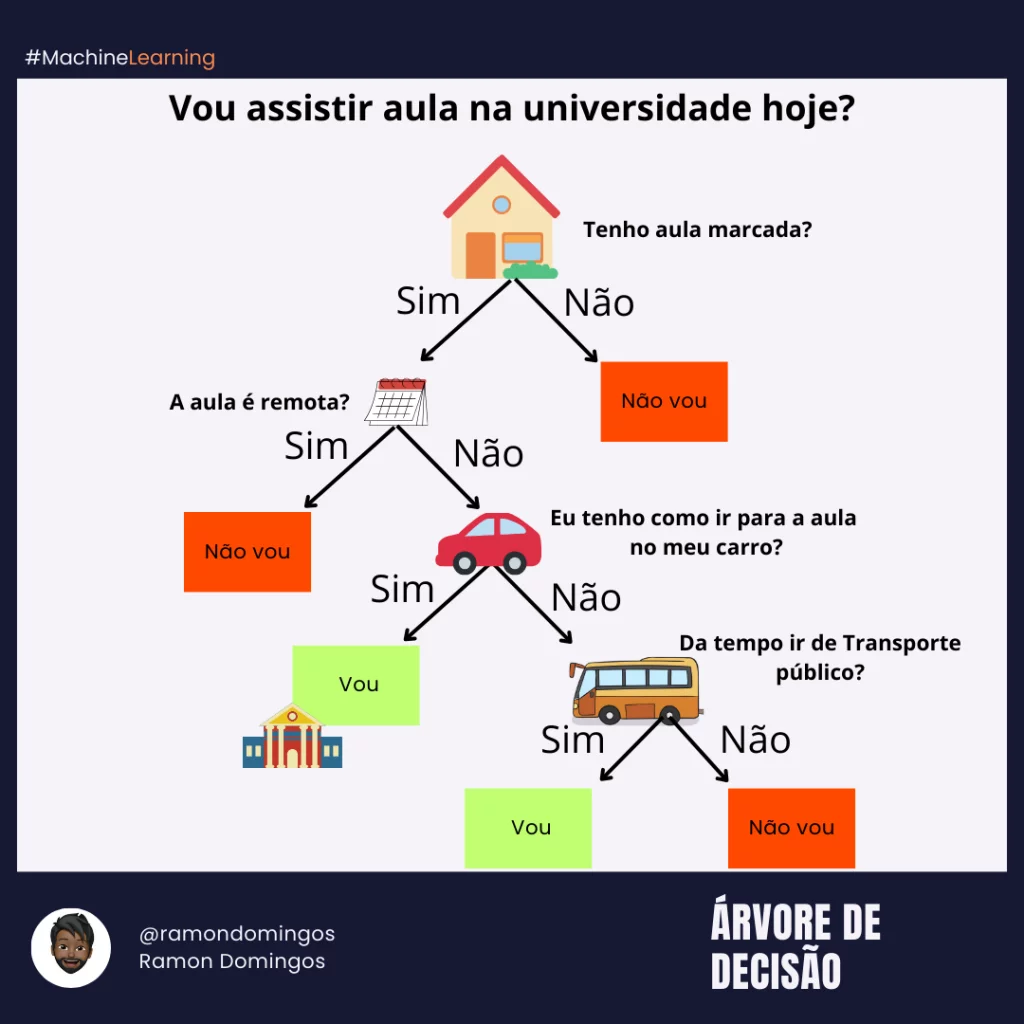
Super simples de entender, certo?
Temos também o Random Forest.
Random Forest
O Random Forest é um algoritmo de ensemble que utiliza múltiplas Árvores de Decisão para melhorar a precisão e reduzir o risco de overfitting (superajuste).
Cada árvore no modelo é construída com um subconjunto aleatório dos dados e das características.
A previsão final é feita por votação (no caso de classificação) ou por média (no caso de regressão) das previsões das várias árvores.
Vamos a análise prática com uma imagem de referência:
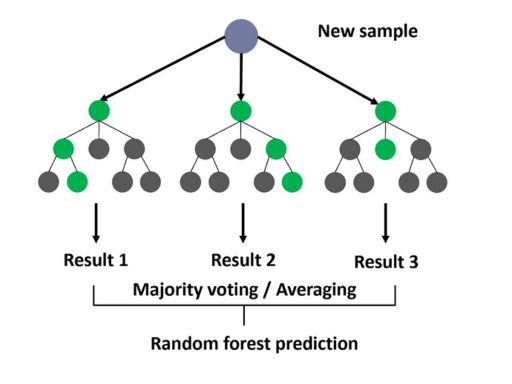
Vamos compreender o fluxo das etapas:
New sample (Nova amostra): Representa os dados de entrada que queremos classificar ou fazer uma previsão.
Árvores de decisão (círculos verdes e cinzas): Cada árvore de decisão é um modelo individual dentro da floresta. Elas dividem os dados em subconjuntos com base em diferentes características, buscando a melhor separação entre as classes ou a melhor previsão para um valor contínuo.
Result 1, Result 2, Result 3 (Resultados 1, 2 e 3): Cada árvore de decisão produz um resultado individual para a nova amostra.
Majority voting / Averaging (Votação majoritária / Média): Os resultados de todas as árvores são combinados. Em problemas de classificação, a classe mais frequente entre as previsões das árvores é escolhida como a previsão final do Random Forest (votação majoritária).
Em problemas de regressão, a média dos valores previstos pelas árvores é usada como a previsão final.
Random forest prediction (Previsão do Random Forest): O resultado final, obtido pela combinação das previsões das árvores individuais.
Exemplo Prático (Famoso): Previsão de inadimplência em uma carteira de empréstimos, onde o Random Forest analisa múltiplas variáveis, como histórico de crédito, renda e histórico de pagamentos, para fazer uma previsão robusta.
Algoritmos de Agrupamento (Clustering)
K-means
O K-means é um algoritmo de clustering que agrupa os dados em K clusters (ou grupos) distintos.
O algoritmo funciona atribuindo cada ponto de dados ao cluster mais próximo com base na média dos pontos em cada cluster (o centróide).
K-means é eficiente e é amplamente usado para segmentação de clientes, análise de mercado e outros problemas onde a estrutura subjacente dos dados precisa ser descoberta.
Hierarchical Clustering
Diferente do K-means, o Hierarchical Clustering cria uma árvore de clusters, conhecida como dendrograma.
Esse algoritmo pode ser aglomerativo (inicia cada ponto de dados como um cluster individual e os combina de maneira hierárquica) ou divisivo (começa com um único cluster e o divide iterativamente).
É útil quando a estrutura dos dados é hierárquica ou quando não se conhece previamente o número de clusters.
Exemplo Prático: Agrupamento de genes com base em expressões semelhantes em estudos de biologia molecular, onde as relações hierárquicas entre genes são importantes.
Support Vector Machines (SVM)
O Support Vector Machines (SVM), é um poderoso algoritmo de classificação que trabalha com a ideia de encontrar um hiperplano que separa os dados em diferentes classes com o maior margem possível entre as classes.
O SVM é eficaz em espaços de alta dimensionalidade e é versátil o suficiente para ser usado em problemas de regressão (Support Vector Regression – SVR) além de classificação.
Ele pode utilizar diferentes tipos de funções kernel (cálculos) para transformar os dados e encontrar o hiperplano ideal, tornando-o uma escolha flexível para vários tipos de problemas.
Imagine que você tem um conjunto de dados que não podem ser separados por uma linha reta.
As funções kernel “transformam” esses dados para um espaço de dimensão mais alta, onde eles podem se tornar linearmente separáveis.
É como se você pegasse um mapa plano e o transformasse em um globo 3D, permitindo traçar rotas que antes pareciam impossíveis.
Como na imagem abaixo:
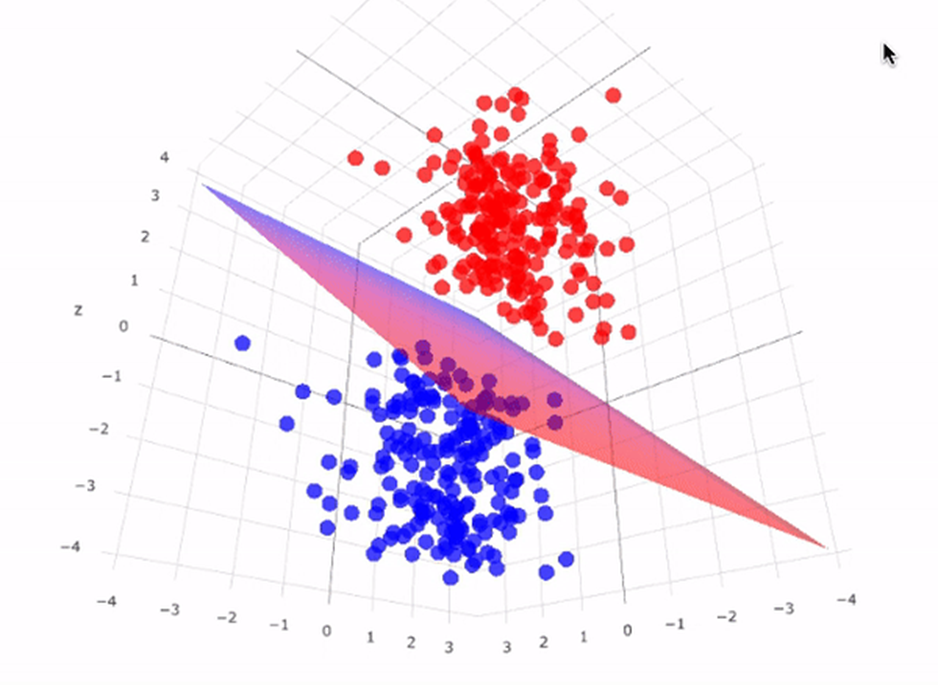
Na prática, o algoritmo SVM pode ser usado para classificar imagens em diferentes categorias.
Cada imagem é representada como um vetor de características, que podem ser pixels, histogramas de cores, ou características extraídas por redes neurais.
Lembra do nosso exemplo de reconhecimento de Vacas, Camelos e Elefantes?
O SVM vai encontrar o hiperplano que melhor separa estas diferentes classes de imagens no espaço de características, fazendo os agrupamentos (clusters) das espécies.
Cada um desses algoritmos que acabamos de estudar desempenha um papel vital no campo do Machine Learning, e a escolha do algoritmo certo depende da natureza dos dados e do problema que se deseja resolver.
Em muitos casos, a eficácia de um modelo não depende apenas do algoritmo escolhido, mas também de como ele é ajustado e combinado com outros modelos para maximizar a performance.
Aplicações Práticas de Machine Learning
Machine Learning (ML) tem transformado diversos setores ao permitir que sistemas automatizados realizem tarefas complexas e tomem decisões baseadas em dados.
Abaixo, exploramos algumas das aplicações práticas mais impactantes de ML em diferentes áreas, destacando como essa tecnologia está sendo usada para melhorar a experiência do usuário, otimizar processos e criar novas oportunidades de negócios.
Recomendação em Compras e Streaming
E-commerce: Esses sistemas utilizam algoritmos de ML para analisar o comportamento de compra de cada cliente, como histórico de navegação, itens visualizados, e compras anteriores, para sugerir produtos que o cliente tem maior probabilidade de comprar.
Com base nos hábitos de compra e navegação dos clientes, a Amazon sugere produtos que são relevantes para cada usuário, aumentando a probabilidade de conversão e fidelidade do cliente.
Streaming de Mídia: Recomendação de Conteúdo em plataformas de streaming como Netflix e Spotify, usam sistemas de recomendação com ML e desempenham um papel crucial ao sugerir filmes, séries, músicas e podcasts que correspondem aos gostos e preferências do usuário.
Chatbots e Assistentes Virtuais
Automação de Atendimento ao Cliente com Chatbots e assistentes virtuais, como os usados por empresas de telecomunicações, bancos e serviços online, são alimentados por algoritmos de ML que permitem a esses sistemas entender e responder a perguntas em linguagem natural.
Esses sistemas utilizam processamento de linguagem natural (NLP) para interpretar as consultas dos usuários e fornecer respostas precisas e úteis em tempo real.
Ao aprender com interações anteriores, o chatbot melhora continuamente sua capacidade de fornecer respostas mais precisas e relevantes, reduzindo a necessidade de intervenção humana e melhorando a eficiência do atendimento ao cliente.
Assistentes Virtuais Pessoais
Assistentes virtuais como Siri, Alexa e Google Assistant utilizam ML para entender comandos de voz, realizar tarefas e fornecer informações relevantes.

Eles são capazes de aprender as preferências do usuário ao longo do tempo, personalizando as respostas e sugerindo ações com base nos hábitos e no histórico de interações do usuário.
Visão Computacional
Reconhecimento Facial Visão computacional é um dos campos onde ML tem feito avanços notáveis, especialmente no reconhecimento facial.
Esse tipo de tecnologia é usado em uma variedade de aplicações, desde a segurança até a personalização de serviços.

Na foto acima, uma câmera de segurança pode estar conectada a um sistema que utiliza ML para identificar objetos, pessoas, tipos placas e modelos de veículos que transitaram em determinada hora do dia ou noite, etc.
Já o reconhecimento facial utiliza algoritmos de ML para identificar e verificar indivíduos com base em características faciais, mesmo em ambientes desafiadores.
A tecnologia de reconhecimento facial usada nos iPhones (Face ID) permite que os usuários desbloqueiem seus dispositivos simplesmente olhando para eles.
Monitoramento e Análise de Vídeo Além do reconhecimento facial, a visão computacional também é usada para analisar vídeos em tempo real, identificando objetos, ações ou eventos específicos.
Em estádios de futebol, por exemplo, câmeras equipadas com algoritmos de visão computacional monitoram o movimento dos jogadores, analisam a velocidade, e fornecem dados em tempo real para comentaristas e treinadores, ajudando a otimizar o desempenho do time.
Reconhecimento de Voz
Conversão de Fala em Texto
O reconhecimento de voz, uma subárea de linguagem natural (NLP), tem se tornado uma ferramenta fundamental em dispositivos que necessitam converter fala em texto.
Aplicativos como assistentes virtuais, softwares de transcrição e sistemas de controle por voz utilizam ML para interpretar e transcrever a fala com alta precisão.
O Google Voice, por exemplo, uma ferramenta de transcrição de voz, usa algoritmos de ML para converter automaticamente o que é dito em texto.
Você provavelmente já viu o processo de geração de legendas automáticas no YouTube ou até mesmo IAs na internet que geram transcrições a partir de vídeos ou urls de vídeos.
Isso é especialmente útil para criar documentos a partir de ditados, enviar mensagens sem precisar digitar, ou ajudar pessoas com dificuldades de mobilidade a interagir com dispositivos eletrônicos.
Vamos analisar o básico destes sistemas a partir da imagem abaixo:
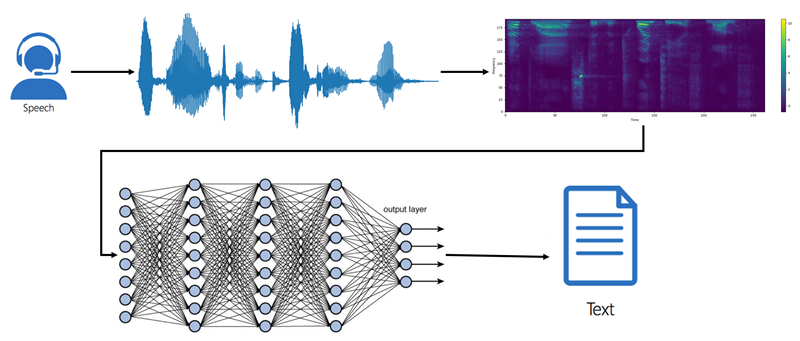
Entrada de Áudio (Speech): O processo começa com a captura do áudio, que pode ser a fala de uma pessoa, uma gravação ou qualquer outra fonte sonora.
Representação Visual do Áudio: O áudio bruto é então convertido em uma representação visual, geralmente um espectrograma.
Espectrograma: Mostra como as frequências do som mudam ao longo do tempo. As cores no espectrograma indicam a intensidade de cada frequência em um determinado momento.
Rede Neural (Neural Network): O espectrograma é alimentado em uma rede neural, que é o coração do sistema de aprendizado profundo de máquina (podendo ser aqui uma IA Generativa).
Saída de Texto (Text): A IA processa o espectrograma e gera uma sequência de caracteres ou palavras que representam o texto transcrito do áudio original.
Comando de Voz em Dispositivos
Além da transcrição, o reconhecimento de voz é amplamente utilizado para controlar dispositivos através de comandos de voz.
Isso inclui desde controlar a reprodução de música em dispositivos de som até ativar funcionalidades específicas em automóveis, como ajustar a temperatura do ar condicionado ou iniciar uma rota no GPS.
Exemplo Prático: No sistema de infotainment dos carros Tesla, os motoristas podem usar comandos de voz para ajustar várias configurações do carro, como temperatura interna, navegação e entretenimento.
Vantagens e Desafios do Machine Learning
O uso de Machine Learning (ML), como você viu junto comigo até aqui, oferece inúmeras vantagens que têm impulsionado sua adoção em diversas indústrias.
No entanto, essa tecnologia também apresenta desafios significativos que precisam ser enfrentados para maximizar seu potencial.
A seguir, discutimos as principais vantagens e os desafios mais críticos associados ao ML.
Vantagens do Machine Learning
Automação e Eficiência
Uma das maiores vantagens do ML é sua capacidade de automatizar processos complexos, o que resulta em um aumento significativo da eficiência.
Sistemas de ML podem processar grandes volumes de dados em tempo real, identificar padrões e tomar decisões de maneira autônoma.
Isso não só economiza tempo, mas também permite que as empresas operem em uma escala muito maior do que seria possível com intervenção humana.
Pode ter certeza, TODAS AS EMPRESAS de grande porte que você conhece utilizam ML.
Melhoria Contínua e Adaptabilidade
Sistemas de ML são projetados para aprender e melhorar continuamente à medida que são expostos a mais dados.
Isso significa que, com o tempo, esses sistemas se tornam mais precisos e eficazes, adaptando-se a novas informações e condições sem a necessidade de reprogramação manual.
Essa capacidade de autoaperfeiçoamento é crucial em ambientes dinâmicos onde as condições mudam rapidamente.
Os algoritmos de detecção de fraude em transações financeiras evoluem continuamente para identificar novos padrões de fraude à medida que surgem, tornando-se mais eficazes ao longo do tempo.
Além disto, ML é amplamente utilizado no mercado financeiro para análises de risco, compra e venda de ações, entre outros.
O ML já deixou muita gente multimilionária dentro e fora do Brasil, sejam os técnicos ou os escritórios de gestão financeira e investimentos que contratam estes tipos de profissionais e serviços.
Capacidade de Lidar com Grandes Volumes de Dados
O ML é a ferramenta quando o assunto é a análise de dados em tempo e qualidade que seriam impossíveis para qualquer ser humano (mesmo o mais inteligente que você conhece ou que já caminhou nesta terra).
Com a explosão de big data, o ML permite que as empresas extraiam insights valiosos de conjuntos de dados massivos que seriam impossíveis de analisar manualmente no seu excel.
Isso possibilita a descoberta de correlações, tendências e padrões ocultos, que podem ser utilizados para melhorar a tomada de decisões.
Personalização e Experiência do Usuário
O ML capacita as empresas a fornecer experiências altamente personalizadas aos seus clientes.
Ao analisar dados comportamentais e preferências individuais, os sistemas de ML podem ajustar ofertas, conteúdo e recomendações para atender melhor às necessidades específicas de cada usuário, o que aumenta a satisfação e a lealdade do cliente.
Nós já falamos aqui sobre Amazon, NetFlix, Spotify, Youtube e etc.
Desafios do Machine Learning
Necessidade de Grandes Quantidades de Dados Rotulados
Uma das principais limitações do ML, especialmente no aprendizado supervisionado, é a necessidade de grandes volumes de dados rotulados para treinar os algoritmos de forma eficaz.
Já falamos sobre estes tipos de dados acima.
A coleta, rotulagem e curadoria desses dados podem ser dispendiosas e demoradas, além de suscetíveis a erros humanos.
Aliás, complementando, a maior quantidade de tempo e planejamento em um projeto que envolve ML tende a ser justamente na etapa de coleta e organização dos dados que irão treinar o modelo.
Em reconhecimento de imagens, por exemplo, um grande desafio é reunir um banco de dados suficientemente extenso de imagens rotuladas, o que pode envolver milhares de horas de trabalho manual para garantir que os dados sejam precisos e abrangentes.
Complexidade e Custo de Implementação
O desenvolvimento e a implementação de soluções de ML podem ser complexos e caros.
Além da necessidade de dados, a criação de modelos precisos requer especialistas em ciência de dados, infraestrutura computacional robusta e tempo para desenvolver, testar e ajustar os modelos.
Esse nível de investimento pode ser impossível para pequenas e médias empresas.
A infraestrutura utilizada, por exemplo, na construção da nova família de modelos Llama 3, é da ordem de bilhões de reais.
Problemas de Interpretabilidade e Transparência
Muitos algoritmos de ML, especialmente modelos complexos como redes neurais profundas (Deep Learning), são frequentemente descritos como “caixas-pretas” devido à dificuldade de entender como exatamente eles chegam a determinadas decisões.
Essa falta de transparência pode ser problemática, especialmente em setores onde a explicabilidade das decisões é crucial, como saúde e finanças.
Alguns avanços notáveis neste sentido tem sido trabalhados pela empresa Anthropic, você pode ler uma matéria explicando como a organização tem desvendado estas “caixas-pretas”, clicando aqui.
Viés e Questões Éticas
Os modelos de ML podem perpetuar ou até amplificar vieses existentes nos dados com os quais foram treinados.
Se os dados de treinamento contêm preconceitos sociais, econômicos ou raciais, o modelo pode produzir resultados injustos ou discriminatórios.
Esse é um dos desafios éticos mais significativos na aplicação de ML e exige uma cuidadosa consideração e mitigação.
Sistemas de reconhecimento facial que foram treinados predominantemente com imagens de pessoas de determinadas etnias podem apresentar taxas de erro mais altas ao reconhecer pessoas de outras etnias, o que levanta sérias preocupações éticas e legais.
Segurança e Privacidade de Dados
À medida que os sistemas de ML se tornam mais integrados em aplicações críticas, a segurança e a privacidade dos dados usados para treiná-los se tornam uma preocupação crescente.
Em sistemas de diagnóstico médico assistidos por ML, há riscos significativos associados à privacidade dos dados dos pacientes e à segurança do sistema contra ataques que possam comprometer a precisão dos diagnósticos.
Felipe, tem cursos online (que valem a pena) gratuitos sobre ML?
Claro, eu vou te indicar duas opções de ótima qualidade e que estão disponíveis até a data da publicação desta matéria (acabei de checar).
Temos uma série de cursos ofertados pela Kaggle, uma famosa plataforma internacional sobre ciência de dados, IA e ML.
Você pode acessar clicando aqui.
E temos também, claro, o gigante de tecnologia Google, ofertando curso intensivo sobre ML.
Você pode acessar clicando aqui.
Conclusões
Uau! Chegamos ao fim..
Apesar das dicas que acabei de fornecer, este conteúdo em si foi praticamente um Curso sobre ML!
O Machine Learning está no coração da revolução tecnológica que está transformando indústrias e melhorando a vida cotidiana.
Ao permitir que sistemas computacionais aprendam e se adaptem a partir de dados, o ML oferece soluções poderosas para problemas complexos, desde personalizar recomendações de produtos até automatizar tarefas críticas.
No entanto, o uso eficaz de ML também requer atenção cuidadosa aos desafios que ele apresenta, como a necessidade de grandes volumes de dados rotulados, a complexidade da implementação e as preocupações éticas relacionadas ao viés e à privacidade.
À medida que a tecnologia continua a evoluir, é crucial que empresas e profissionais entendam tanto as oportunidades quanto as limitações do ML.
Se cadastre na nossa Newsletter abaixo e fique por dentro das atualizações mundiais sobre Inteligência Artificial gratuitamente, sem propaganda e no seu idioma.
Referências
Oracle, Google, IBM e AmazonWebServices.