

Conteúdo Atualizado em 4 de setembro de 2025 por felipecferreira, enjoy!
A Meta Facebook anunciou o lançamento do LLaMA 3.1, a versão mais recente e avançada de sua família de modelos de linguagem de código aberto.
Este novo modelo visa não apenas superar seus antecessores, mas também competir de frente com alguns dos modelos mais poderosos do mercado, como o GPT-4 da OpenAI e o Claude 3.5 da Anthropic.
Ainda não sabe o que é Inteligência Artificial? Clique Aqui.
O que Muda com o Llama 3.1?
Bom, antes disto, você pode ter tido uma dúvida..
Mas o que é um modelo de código aberto?
O código aberto é um modelo de linguagem de grande escala cujo código-fonte, arquitetura e, muitas vezes, os dados de treinamento são disponibilizados publicamente.
Isso significa que qualquer pessoa pode acessar, modificar, distribuir e usar o modelo para diversos fins, como pesquisa, desenvolvimento de aplicativos ou até mesmo para fins comerciais.
Agora, ao que tudo indica, o Meta Llama 3.1 é o maior e mais capaz modelo de código aberto disponível no mundo.
Com mais de 300 milhões de downloads totais de todas as versões do Llama até o momento, tudo indica que esta história dos modelos open-source, está apenas começando.
Comparando o Llama 3.1 com Concorrentes
Vamos analisar apenas um dos quadros comparativos de performance, que demonstram as avaliações humanas, do Llama 3.1 405B com referência a outros modelos Líderes de mercado.
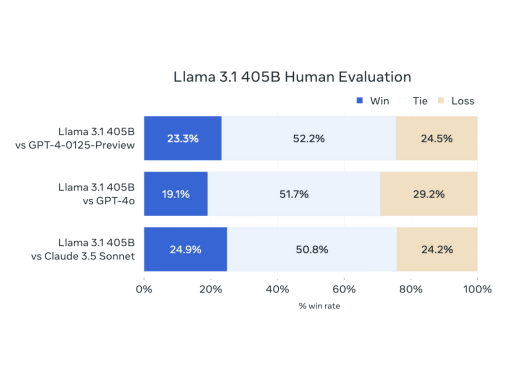
Os dados mostram que, quando comparado a experiência (qualidade em resultados de prompts) de uso do GPT-4-0125, o LLaMA 3.1 obteve uma taxa de performance superior em 23,3% dos casos, empatou em 52,2% das vezes, e foi inferior em 24,5% das análises.
Quando o LLaMA 3.1 é comparado ao GPT-4o, a performance ainda tende a ser inferior.
Comparado com o Claude 3.5 Sonnet, o LLaMA 3.1 mostra uma taxa de “vitória” de 24,9%, empatando em 50,8% das vezes e perdendo em 24,2% dos casos da amostragem de utilização.
Isto indica uma performance mais equilibrada entre o modelo da Meta Facebook e Anthropic.
Se você quer baixar o artigo completo com os dados técnicos detalhados da Meta sobre o Llama 3.1 (em inglês), clique aqui.
A Palavra do CEO, Mark Zuckerberg
Aqui temos um dos principais trechos da carta do CEO da Meta Facebook, sobre este lançamento:

I believe that open source is necessary for a positive AI future. AI has more potential than any other modern technology to increase human productivity, creativity, and quality of life – and to accelerate economic growth while unlocking progress in medical and scientific research. Open source will ensure that more people around the world have access to the benefits and opportunities of AI, that power isn’t concentrated in the hands of a small number of companies, and that the technology can be deployed more evenly and safely across society.
Nossa tradução: Acredito que o código aberto seja fundamental para um futuro positivo da IA. A inteligência artificial tem mais potencial do que qualquer outra tecnologia moderna para aumentar a produtividade, a criatividade e a qualidade de vida humana – além de acelerar o crescimento econômico e desbloquear avanços na pesquisa médica e científica. O código aberto garantirá que mais pessoas em todo o mundo tenham acesso aos benefícios e oportunidades da IA, que o poder não se concentre nas mãos de um pequeno número de empresas e que a tecnologia possa ser implementada de forma mais equitativa e segura em toda a sociedade.
Fonte: Open Source AI Is the Path Forward (por Mark Zuckerberg).
As Diferenças entre os Modelos Llama 3.1
As diferenças entre os modelos LLaMA 3.1 de 8B, 70B e 405B da Meta referem-se principalmente ao tamanho dos modelos em termos de bilhões de parâmetros, o que se reflete na capacidade de processamento e aplicações específicas.
O que são parâmetros em um modelo de linguagem?
Parâmetros são componentes essenciais que ajudam o modelo a aprender e generalizar a partir dos dados de treinamento.
Eles são, em essência, os pesos e vieses dentro das redes neurais que são ajustados durante o processo de treinamento para minimizar a diferença entre as previsões do modelo e os resultados reais.
Quando dizemos que um modelo tem 8 bilhões de parâmetros, estamos nos referindo ao número total de pesos e vieses que a rede neural possui.
Um maior número de parâmetros geralmente indica uma maior capacidade do modelo de aprender padrões complexos e sutilezas a partir dos dados de treinamento (machine learning), embora também aumente a complexidade e os requisitos computacionais pra que o modelo possa funcionar.
Llama 3.1 de 8B
Este é o menor modelo da série, ideal para aplicações que necessitam de menor poder computacional e podem operar com recursos mais limitados (aproximadamente 4.7 GB).
É adequado para tarefas que não exigem um contexto extremamente longo ou processamento intensivo.
O Llama 3.1 8B pode ser utilizado em dispositivos com menor capacidade de processamento, como alguns smartphones e aplicações embarcadas.
Llama 3.1 de 70B
Este é o modelo intermediário que oferece um equilíbrio entre capacidade e eficiência (aproximadamente 40 GB).
É adequado para uma ampla gama de aplicações, incluindo chatbots avançados, sistemas de recomendação e análise de dados complexos.
Este modelo pode ser implementado em servidores de médio a grande porte, adequado para empresas que necessitam de soluções de IA robustas mas acessíveis.
Llama 3.1 de 405B
Este é o maior e mais avançado modelo da série, destinado a tarefas que exigem processamento intensivo e a capacidade de lidar com contextos extremamente longos (aproximadamente 430 GB).
É ideal para pesquisa avançada, análise de grandes volumes de dados e desenvolvimento de tecnologias de ponta.
O modelo necessita de infraestrutura de alta capacidade, como servidores com GPUs de última geração (projetos maiores).
Se quer baixar algum destes modelos, clique aqui.
Se quer acessar a documentação completa e oficial da Meta, clique aqui.
Um Pouco Sobre o Funcionamento do Llama 3.1
Treinar o LLaMA 3.1 405B em mais de 15 trilhões de tokens foi um grande desafio (de acordo com a empresa), que exigiu a otimização significativa de todo o processo de treinamento.
Para conseguir isso, a Meta utilizou mais de 16 mil GPUs H100, fazendo do 405B o primeiro modelo LLaMA treinado nesta escala (uma infraestrutura de mais de 4 bilhões de reais).
Para manter o processo de desenvolvimento escalável e simples, optaram por uma arquitetura de transformador apenas com decodificador, realizando apenas pequenas adaptações.
Essa escolha ajuda a maximizar a estabilidade durante o treinamento.
A arquitetura de transformadores consiste em várias camadas que incorporam mecanismos de atenção e redes neurais feedforward, como ilustrado na imagem.
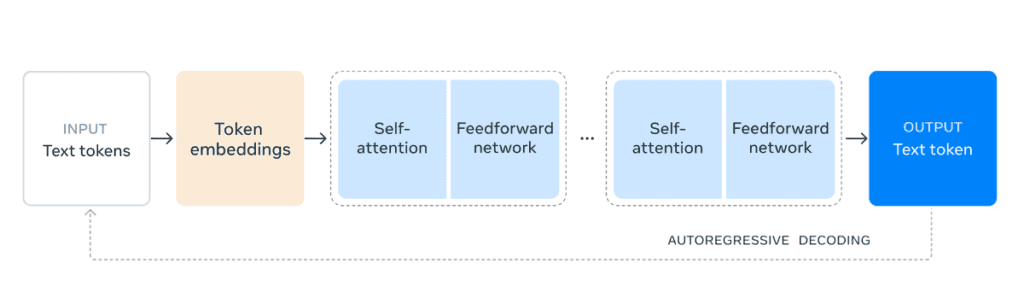
Sim, está em inglês, mas eu vou detalhar cada etapa junto com você.
Entrada (Input) Text Tokens
O processo começa com a entrada de tokens de texto, que são sequências de caracteres ou palavras convertidas em unidades menores e manejáveis chamadas tokens.
Token Embeddings
Esses tokens de texto são transformados em embeddings de tokens.
Embeddings são representações vetoriais densas de tokens que capturam o significado semântico em um espaço dimensional contínuo.
Essencialmente, eles traduzem os tokens de texto em um formato numérico que a rede neural pode processar.
Self-Attention (Mecanismo de Autoatenção)
O modelo aplica o mecanismo de autoatenção (self-attention) aos embeddings de tokens.
A autoatenção permite que o modelo considere o relacionamento de cada token com todos os outros tokens na sequência, ajudando a capturar dependências e contextos a longa distância de forma eficaz.
Feedforward Network
Após a etapa de autoatenção, os embeddings passam por uma rede neural feedforward.
Esta rede consiste em várias camadas de neurônios que processam os embeddings para refinar e transformar ainda mais as representações internas.
Repetição do Processo (Iterações)
O processo de autoatenção seguido pela rede feedforward é repetido várias vezes através de múltiplas camadas (indicadas pelas caixas azuis claras repetidas).
Cada iteração permite ao modelo ajustar e melhorar suas representações internas.
Saída (Output) Text Token
Finalmente, o modelo gera tokens de texto como saída.
Esses tokens são então decodificados de volta para o texto compreensível no idioma desejado, completando o processo de inferência.
Autoregressive Decoding (Decodificação Autoregressiva)
O modelo usa um processo autoregressivo para decodificação, onde a saída de cada etapa é alimentada de volta como entrada para prever o próximo token na sequência.
Isso permite a geração de texto contínuo e coerente.
Conclusões
O lançamento do LLaMA 3.1 representa um avanço importantíssimo no contexto de modelos (IA) de código aberto, oferecendo novas oportunidades para desenvolvimento e pesquisa.
Os dados de benchmark indicam que o LLaMA 3.1 oferece uma performance altamente competitiva em comparação com os modelos GPT-4 e Claude 3.5 Sonnet.
Constatamos que a ampla concorrência continua beneficiando principalmente nós, consumidores, e acelerando o processo de desenvolvimento de novas tecnologias.
Vamos seguir atentos nas análises das próximas novidades.
Aproveite e cadastre-se em nosso portal para receber as últimas atualizações mundiais sobre inteligência artificial, diretamente no seu e-mail, gratuitamente e em português.